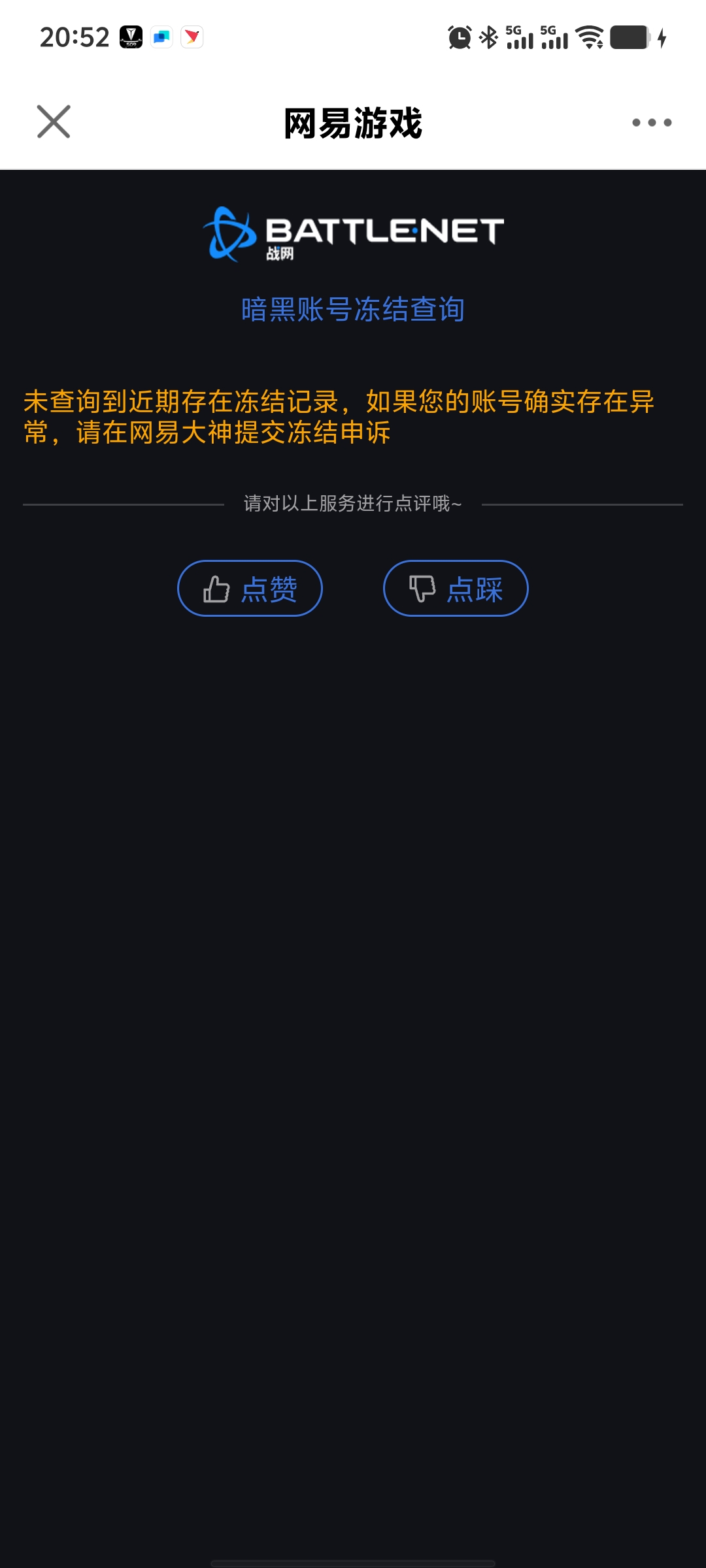
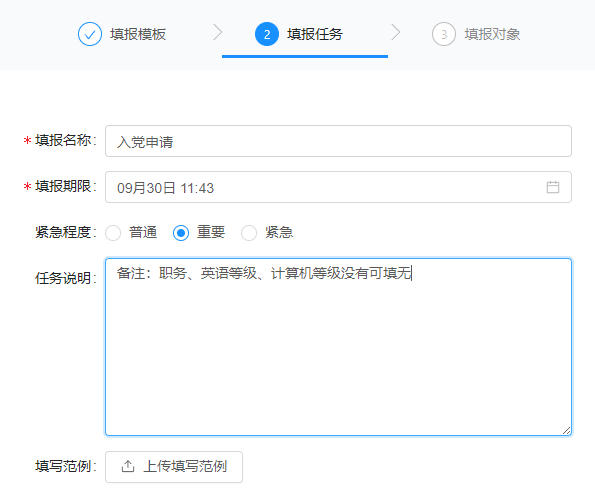
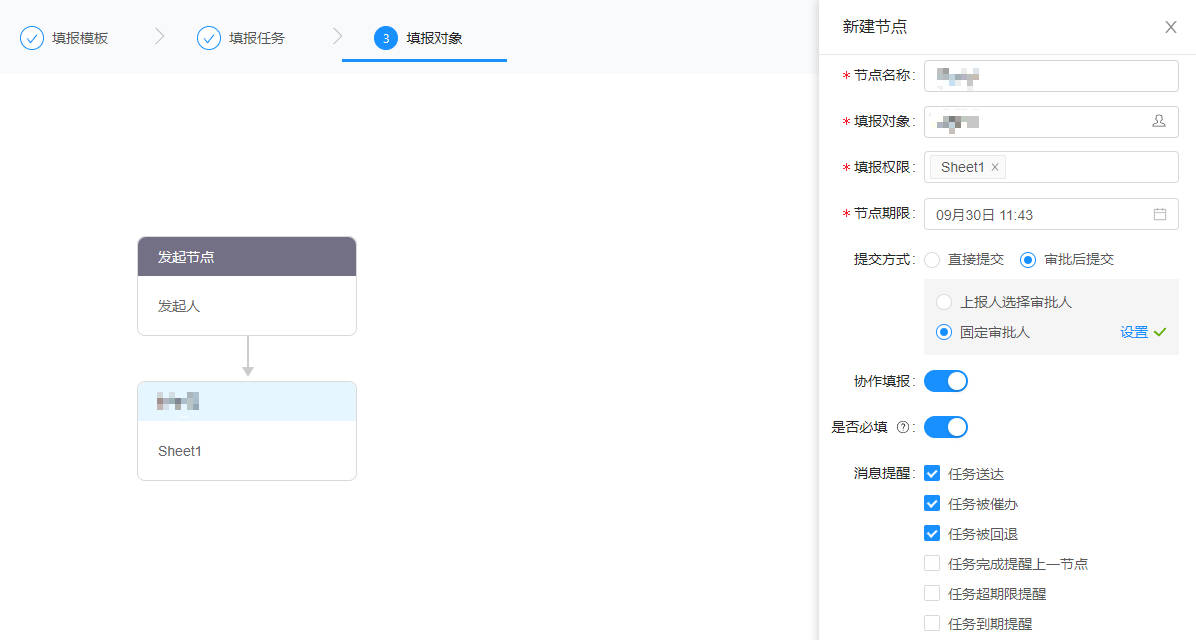
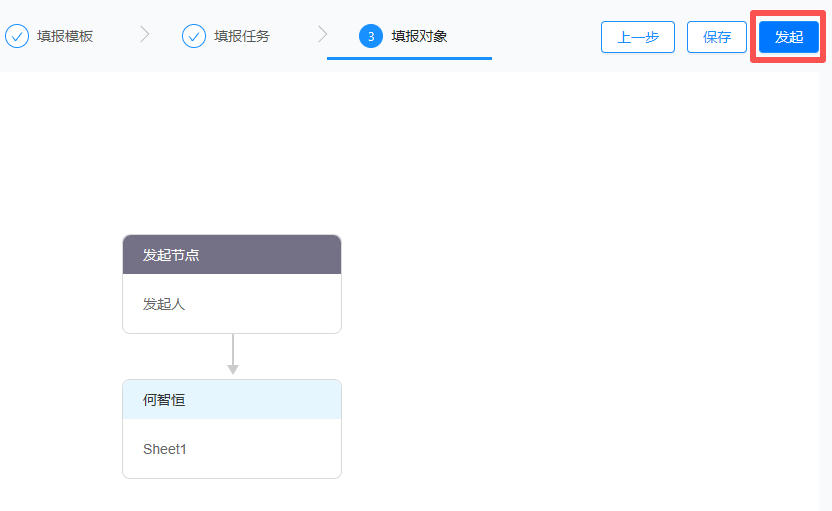
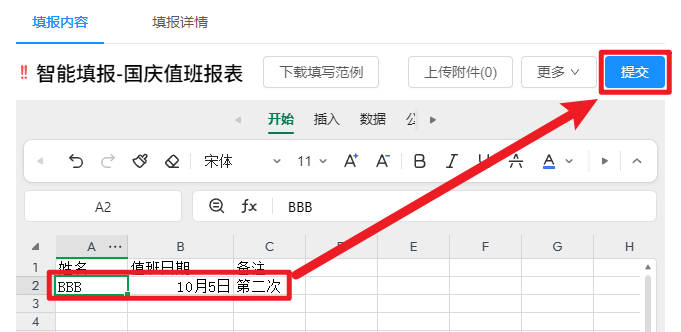
最近,有才的网游“开发”开发了一键投诚APP,也叫归家APP,方便在湾湾的同胞们领鸡蛋、举报“坚臣当道”这样的人…其实呀!回家APP也有正版,一旦要辨明敌我身份的时候,打开手机,出示注册好的账户信息是本人的话,基本就知道是同志了。
學習強國
作为爱好学习的中国人,每天获得有效正确信息,免费学习,认清事实是非常重要的。这个APP是当之无愧的回家神级APP。赖赖、英子这类人是肯定不敢安装的,这是识别家己人(ga¹ gi⁷ lang⁵)的最有效APP了。

國家反詐中心APP
这个APP可以让你防范各种诈骗伎俩,防止赖赖、英子、“坚臣当道”这样的小人是非常有效的工具,记得及时注册,防范风险

国家网络身份认证APP
绿蛙可能会没收你的证件,让你无法有效证明自己是堂堂正正的中国人。没关系,这个国家网络身份认证APP是官方的手机身份证,没有了身份证、居住证、台胞证都可以有效证明自己身份。
各省市的办事APP(服务号)
譬如在广东叫粤省事,在上海叫随申办,i厦门、闽政通…你的身份证、驾驶证、医保社保等一系列的信息都在里面,随时随地办事,让你少跑很多次各个部门单位。本渣去医院看病都是扫粤省事里面的医保码就行,里面有平时五险一金存进去的余额,直接用就可以。
台陆通
虽然是非常小众的APP,但是里面很多有趣的资信可以获得,譬如下图的福州2天1夜移动支付体验旅游团,非常的让人绷不住。很多快递是台湾省不包邮的,可以先寄到一个包邮的地址,再送到自己手上,这样的集中快递比单个包裹跨海便宜多了。


交管12123
如果在路上有轻微违规,一年可以免罚4次的喔,2次主动接受警告,2次看视频抵罚,每各自然年重置一次,分分钟能省一千几百云。最重要是能申领电子驾照,查车的时候不用到处找驾照了。

数字人民币、云闪付、支付宝、微信支付
移动支付方便了生活,不用带零钱、大额现金出门时多么便利的生活方式。前提是你要保管好你的手机,坏了、不见了、被偷了都会让你日常生活寸步难行。出门在外还是带几百元现金傍身比较好。点外卖、打车、坐公交地铁、交水电费…主要是便民服务太方便了。

DeepSeek、豆包、通义千问
虽然ChatGPT很好用,但是谁能抗拒全免费的DeepSeek、豆包、通义千问等随心用的大模型。当年一个ChatGPT账号要几十元美金,还要梯子的日子真的受够了。未来任何APP、手机、汽车都有AI,没有AI都不好意思说自己是一个合格的产品。多问AI让你的生活、工作、学习少走狠多弯路。