各种TTS文字转语音克隆测试
找了很多网上文字转语音的费用都不低,也尝试了很多个本地部署的,最终现在只有Spark TTS成功了,分享一下部署方法。
本渣的电脑配置
CPU: AMD Zen2 3750 4核8线程
GPU:英伟达 1650 4G (没有英伟达显卡可以用CPU来跑)
内存:32G DDR4 2666
硬盘:致态 2T
安装Conda
下载地址:https://repo.anaconda.com/miniconda/
下载最新版的Miniconda3-latest-Windows-x86_64.exe并安装,都是下一步默认安装就好。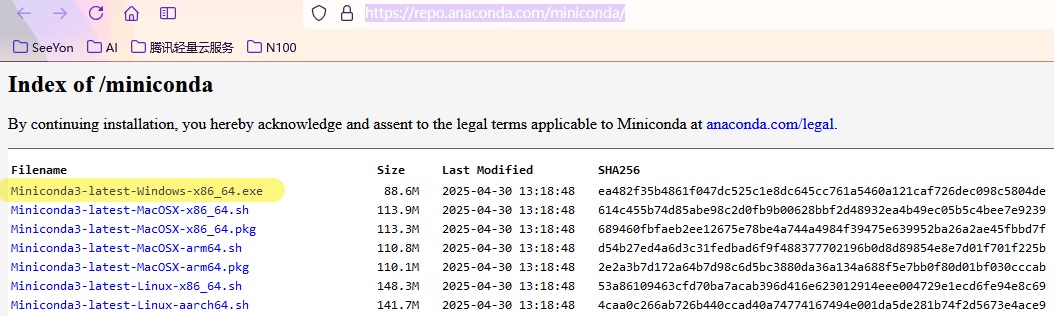
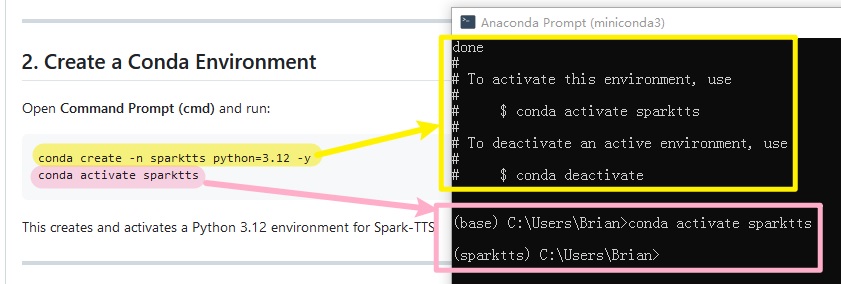
安装完有这个Anaconda Prompt程序在菜单中可以找到,证明成功了,后面在conda的命令都是在这个命令界面运行。
在Anaconda Promp的命令工具运行如下命令
1 | # 确认是否安装好,看看有没有版本号返回 |
CUDA安装(不做这一步就是用CPU来跑)
通过nvidia-smi命令来确认自己的CUDA版本。如我的是12.8。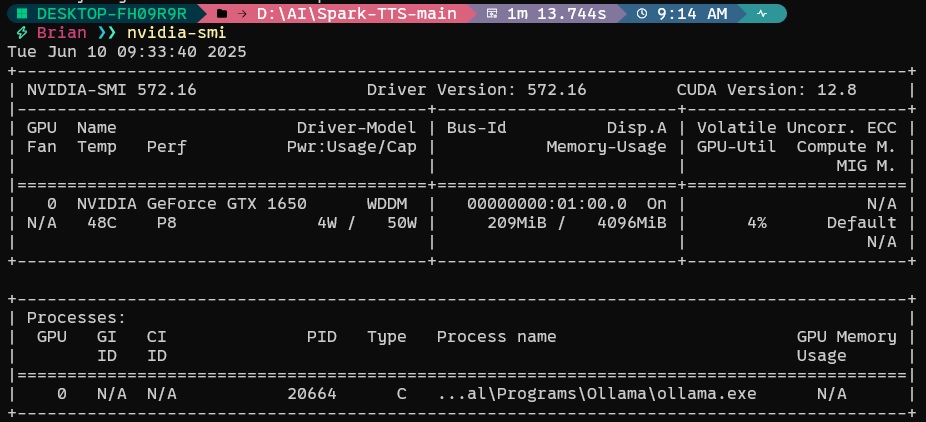
然后在https://developer.nvidia.com/cuda-toolkit-archive找到你对应的版本。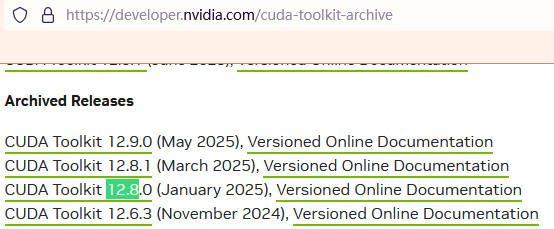
对照自己的系统版本来下载安装好。
执行后续命令前,记得先去下载最新的Python来安装一下,不然无法运行pip命令的。
下载地址是:https://www.python.org/
本以为我的电脑本来在安装Ollama的时候就安装好CUDA了,可以这一步省略了。发现是理解错了。
这里是根据你CUDA版本安装好对应的PyTorch的CUDA版本。
1 | pip install torch torchvision torchaudio --index-url https://pytorch.org/get-started/previous-versions/ |
我的是12.8。所以安装的命令是:
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 |
这个命令可以在官网找到https://pytorch.org/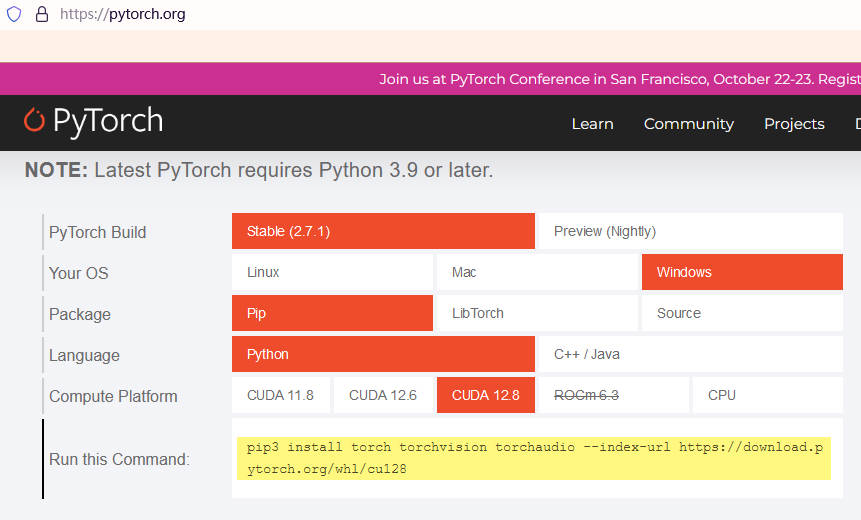
如果你没有英伟达的显卡,可以选择用CPU的语句pip3 install torch torchvision torchaudio。
下载源码ZIP包并安装
下载地址:https://github.com/SparkAudio/Spark-TTS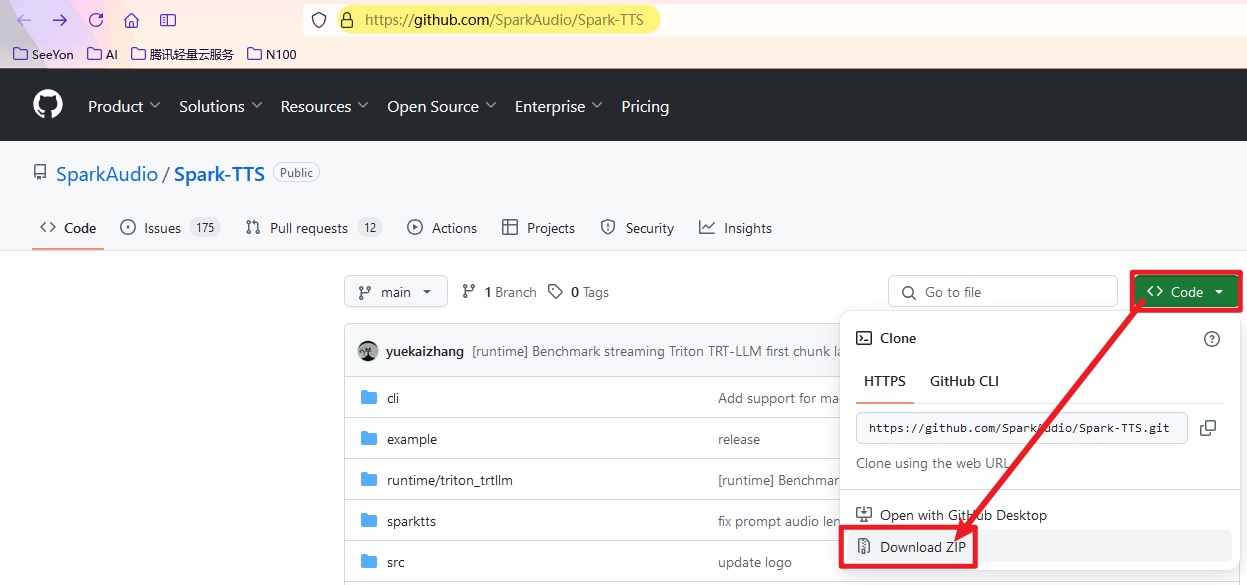
建议用迅雷来下载,不然很可能会失败:https://github.com/SparkAudio/Spark-TTS/archive/refs/heads/main.zip
把ZIP包解压出来D:\AI\Spark-TTS-main,并且在这个目录里面运行终端来跑这个命令。
1 | pip install -r requirements.txt |
命令 pip install -r requirements.txt 是在使用 Python 的包管理工具 pip 来安装依赖文件中列出的所有第三方库。
详细解释:
pip: 是 Python 的默认包管理器,用于安装和管理 Python 库(packages)。-r requirements.txt: 表示从名为requirements.txt的文件中读取要安装的库列表。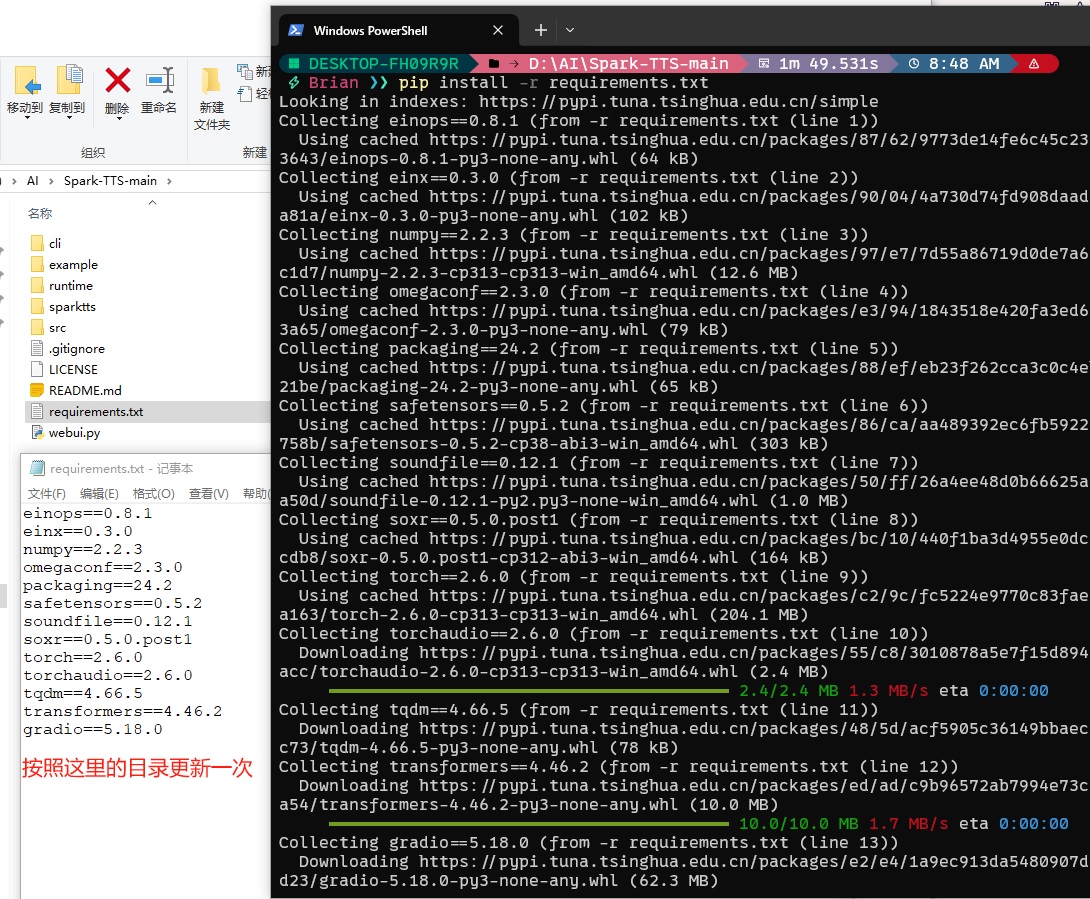
报错01 版本太低
如果你遇到我一样的错误,是因为requirements.txt文件中的torch和torchaudio版本太低,pip的包管理命令不支持自动更新了。改为2.6.0即可。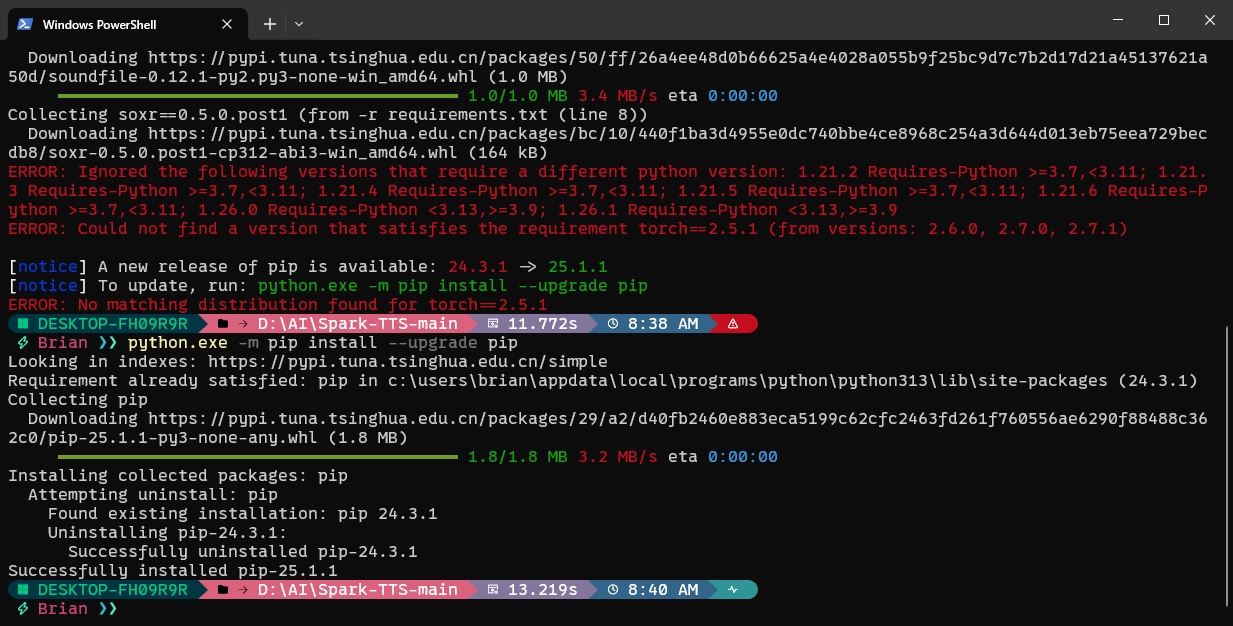
1 | ⚡Brian ❯❯ pip install -r requirements.txt |
报错也让我运行这样的命令,所以也执行了一下。
感觉是是要运行python.exe -m pip install --upgrade pip来升级到25.1.1
重新执行pip install -r requirements.txt的成功界面是这样的,更新了一堆东西。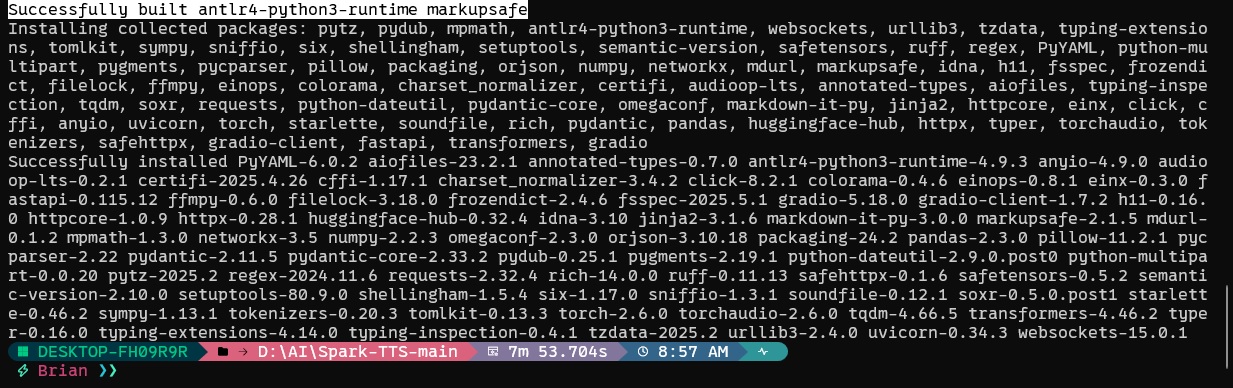
下载模型
1 | # 在Spark-TTS的解压ZIP包的目录中创建文件夹pretrained_models |
报错02 无法下载模型
总所周知,我们有墙,huggingface上的东西是下载不到的。
可以切换到modelscope.cn去下载。
地址是:https://modelscope.cn/models/SparkAudio/Spark-TTS-0.5B/files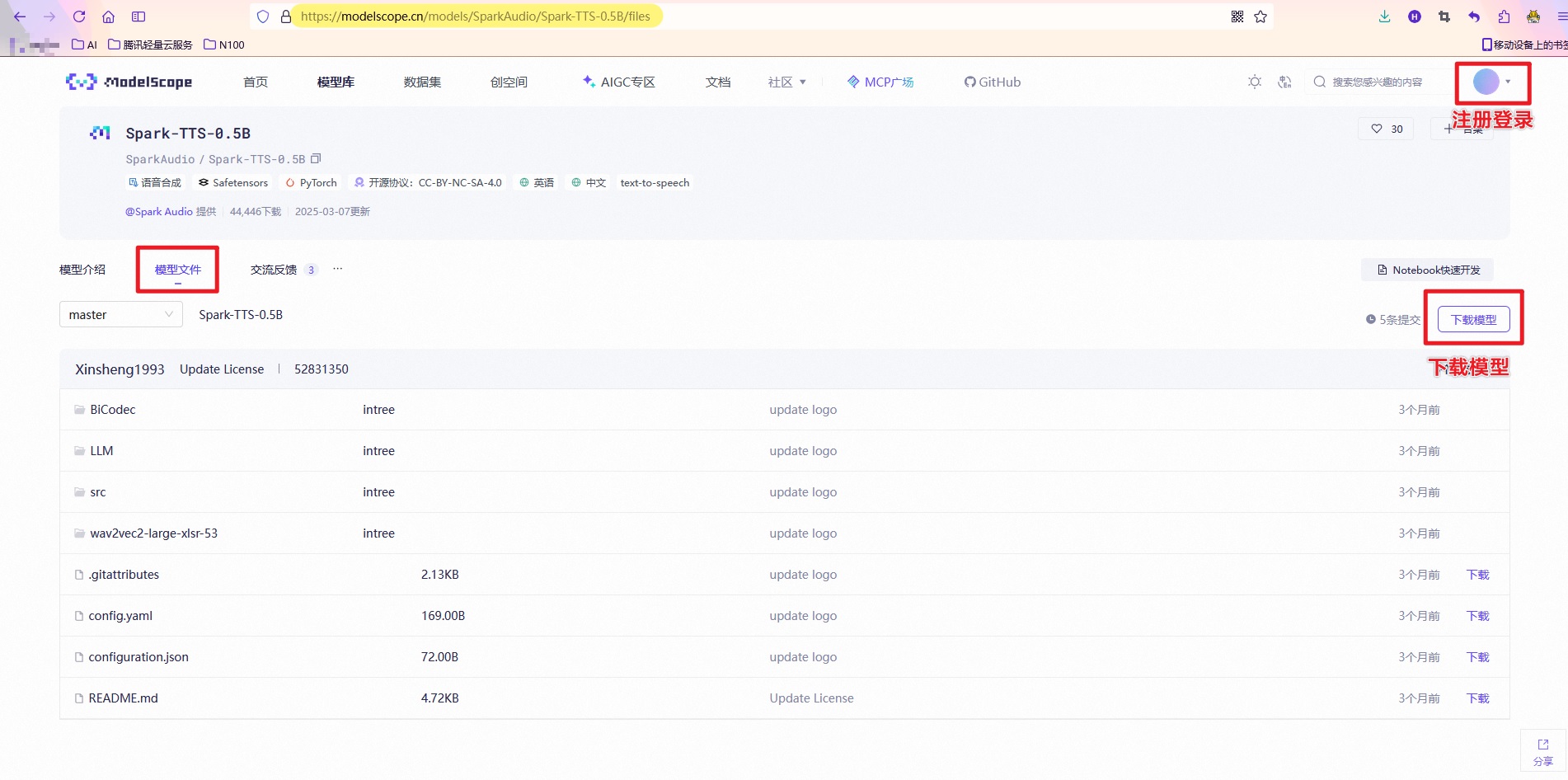
先要安装一下modelscope这个下载工具
1 | pip install modelscope |
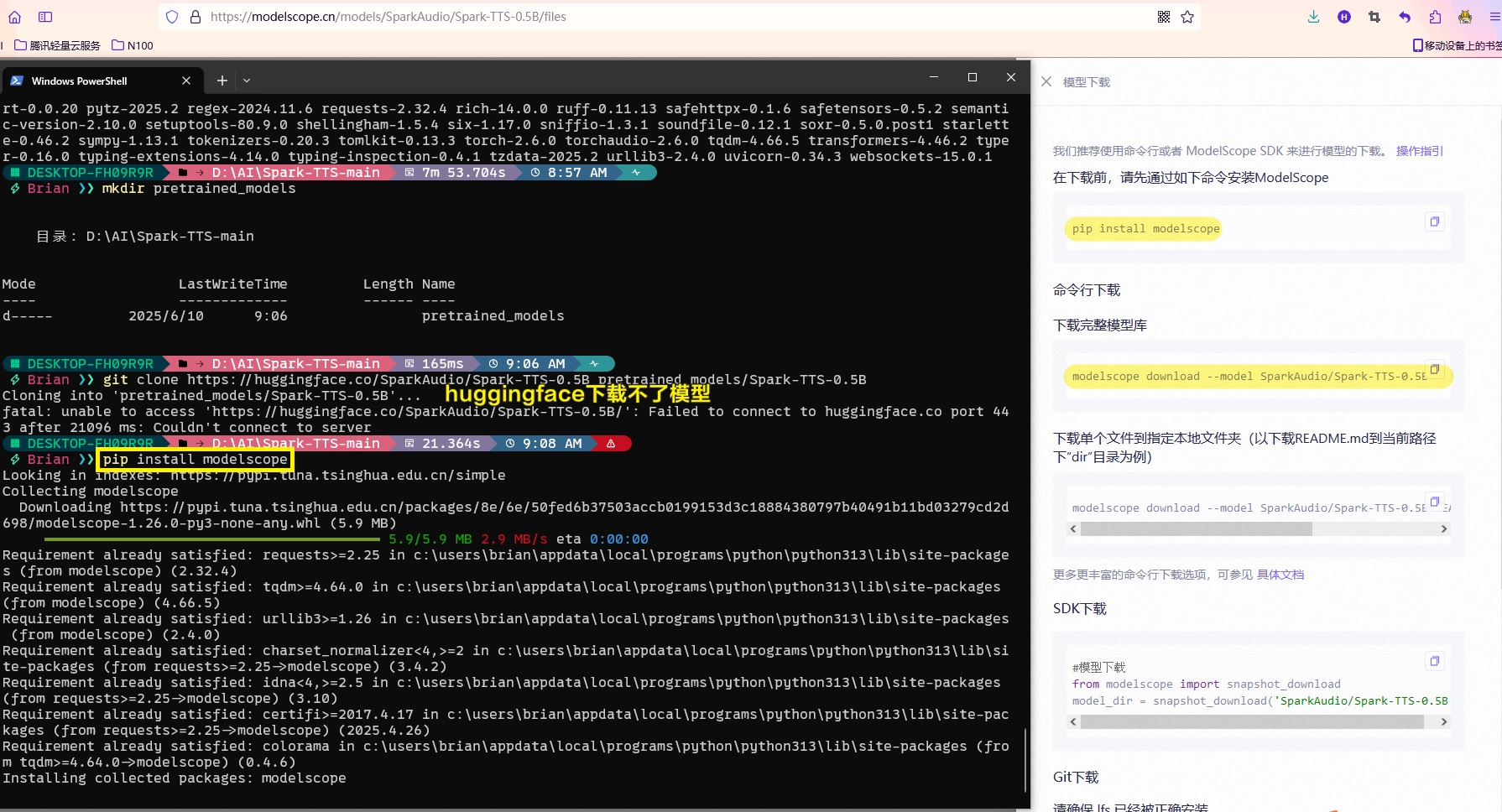
再进行下载,在D:\AI\Spark-TTS-main\pretrained_models目录中打开一个新终端,运行以下语句。
1 | modelscope download --model SparkAudio/Spark-TTS-0.5B |
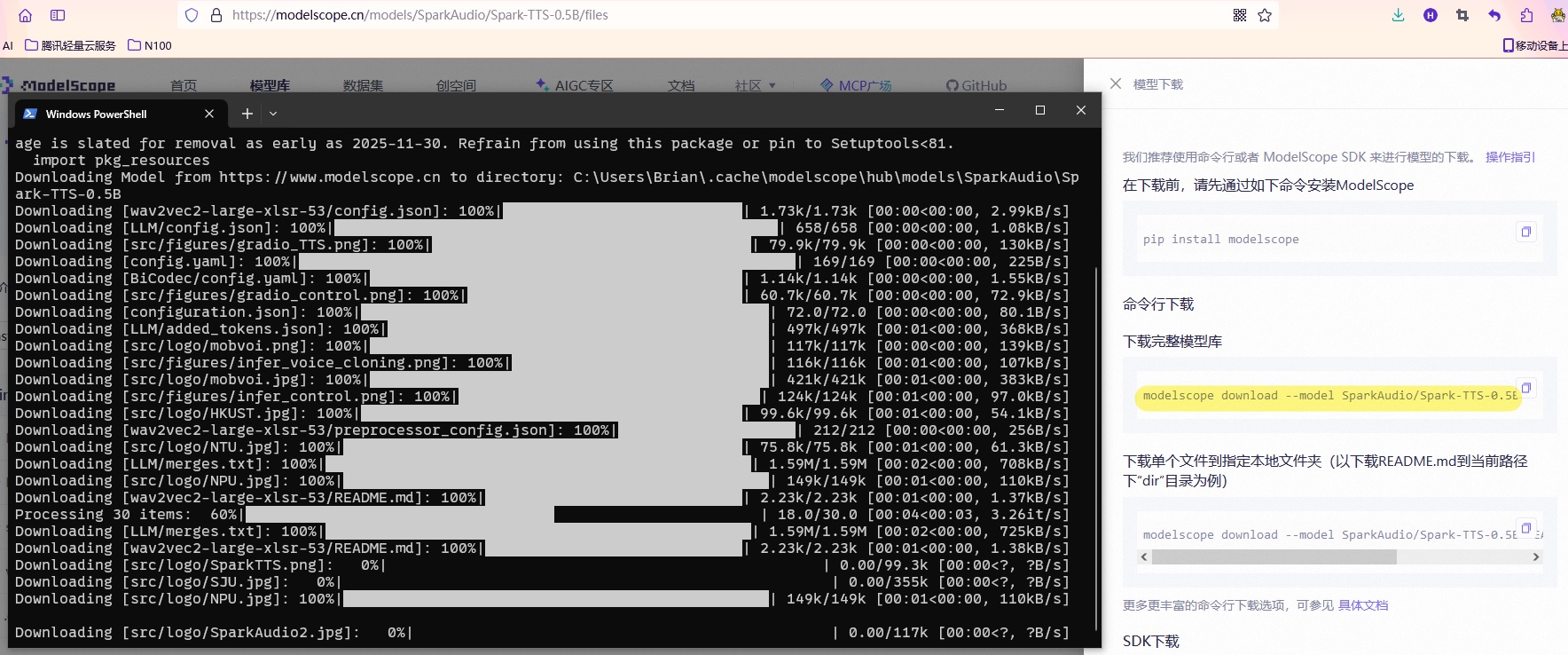
下载完后文件放在了C:\Users\Brian\.cache\modelscope\hub\models\SparkAudio文件名叫Spark-TTS-0___5B
把文件夹制到D:\AI\Spark-TTS-main\pretrained_models并重命名为Spark-TTS-0.5B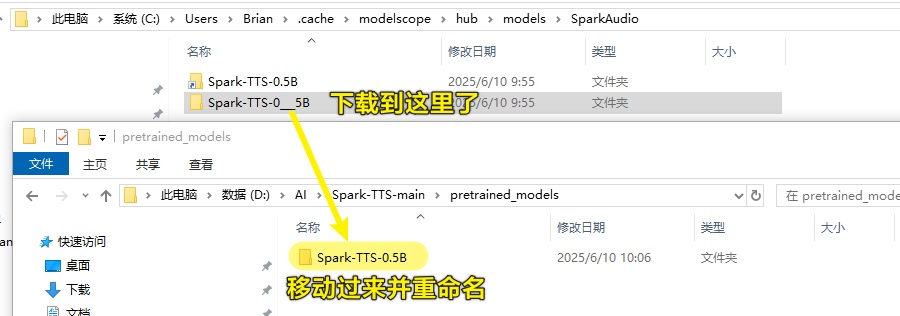
启动Spark TTS
启动的语句是在目录D:\AI\Spark-TTS-main运行命令行来执行这个语句。
1 | python webui.py |
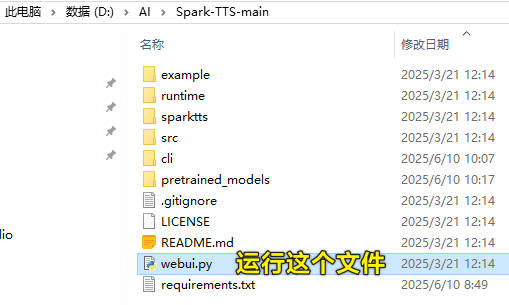
当然,如果你一次成功就看到如下返回值,直接进入http://127.0.0.1:7860/?就能开始使用了。
如果你遇到本渣一样的错误,就继续往下看。
报错03 安装更新Gradio
错误信息返回值
几百行的错误日志,我用AI帮我分析。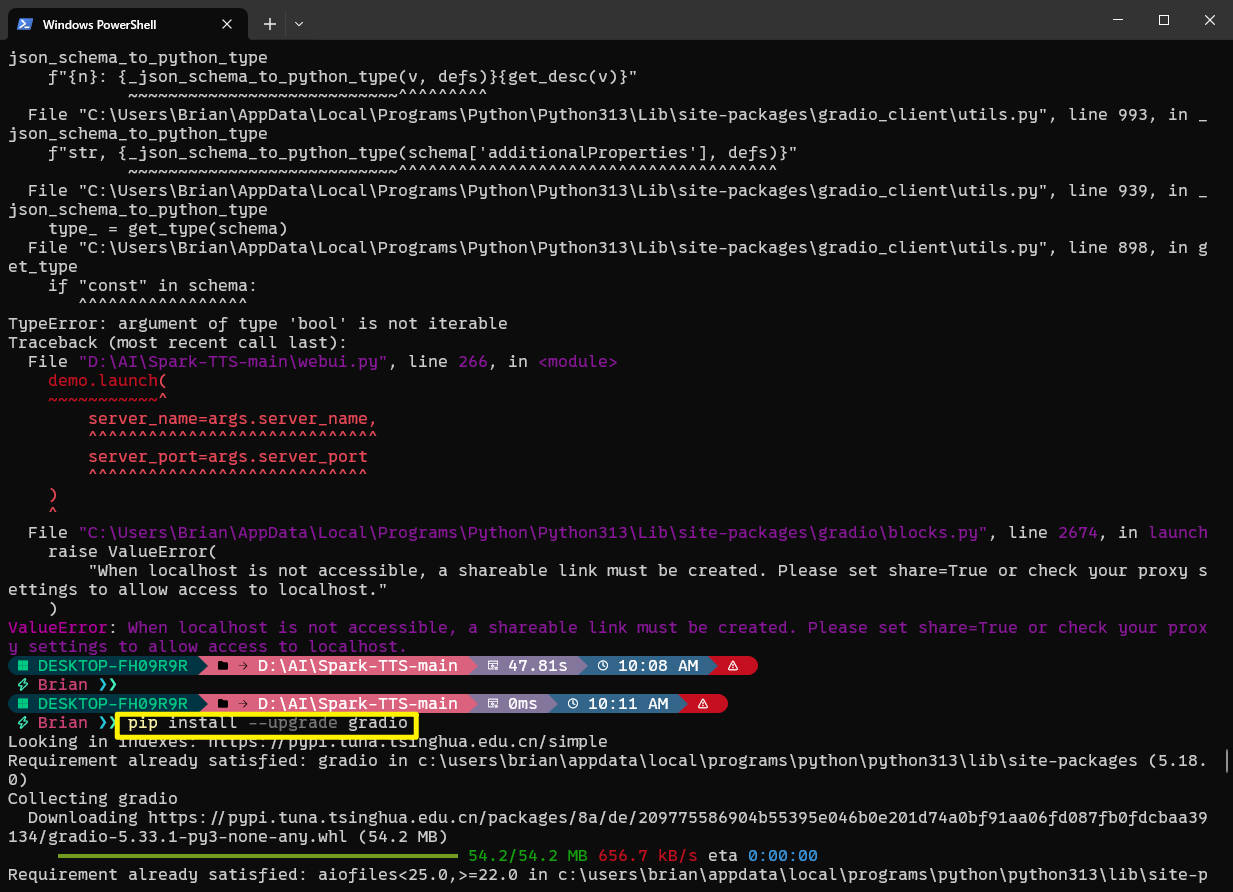
最后我就用这一条语句,安装了Gradio来解决的。
1 | pip install --upgrade gradio |
重新启动
重新执行python webui.py就成功了。需要用浏览器打开http://127.0.0.1:7860/就能去到WebUI界面了。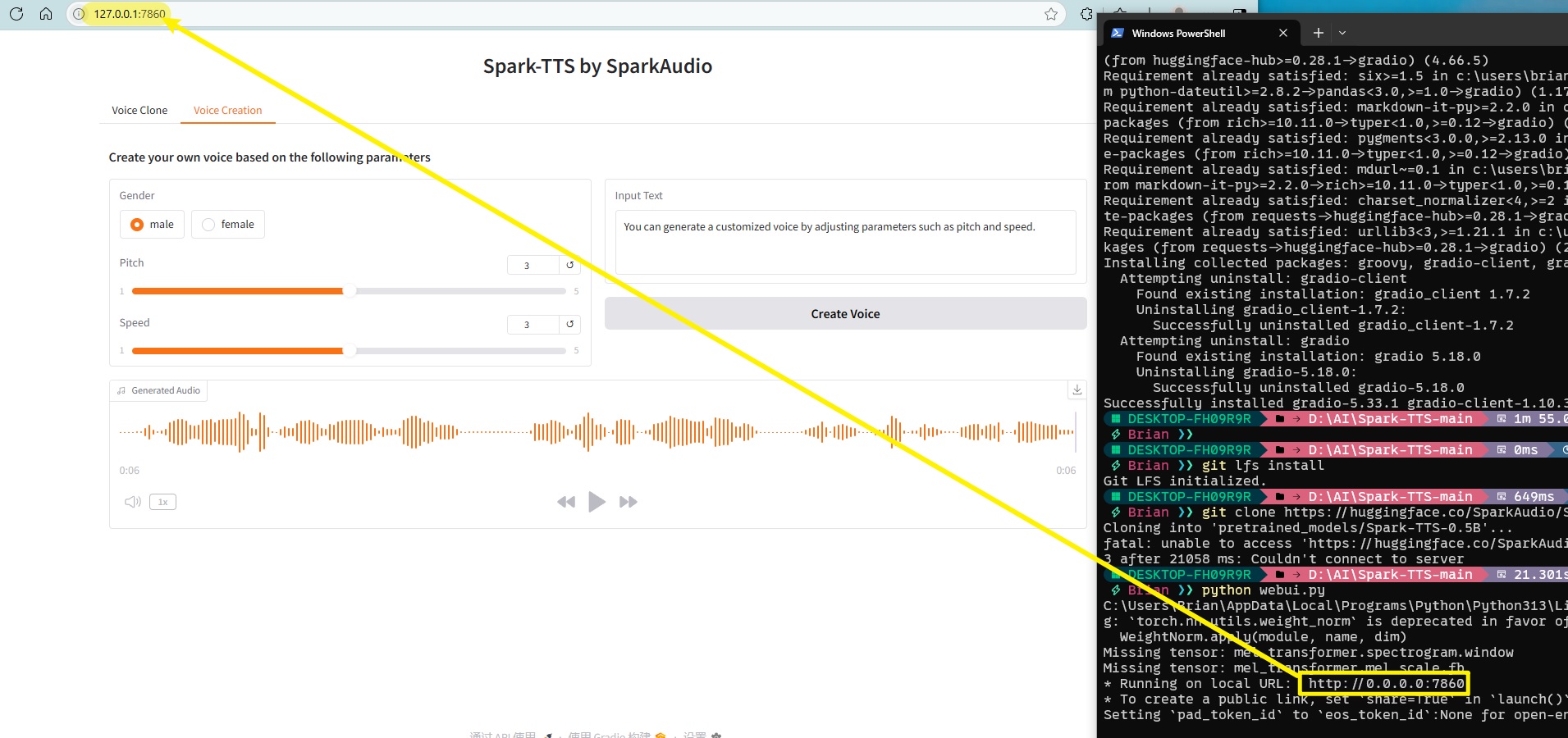
跑完的声音会保存在这个目录D:\AI\Spark-TTS-main\example\results
测试,可以跑得动。但是速度就非常感人。14秒的语音,用了250秒才跑完。感觉是GPU没有跑满导致的,可能是CUDA没有调动起来。但是GPU也跑到35%的占用,真是奇怪。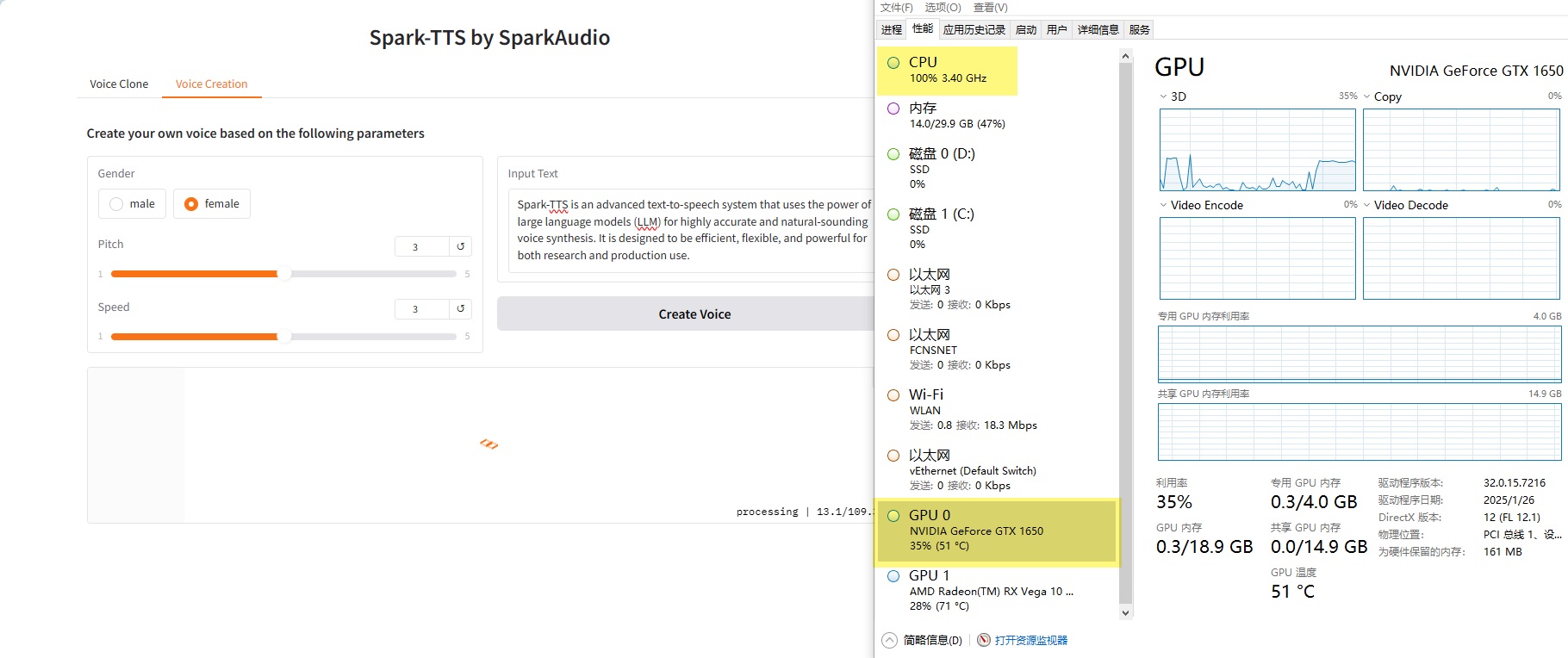
错误04 无法用CUDA跑运算
发现安装的PyTorch是CPU版本,需要重新安装。
1 | # 这个语句用来检查PyTorch版本,如果返回值是False就是CPU版本。 |

1 | # 安装新的PyTorch GPU版本 |
安装了PyTorch GPU版本后,显存占用是上来了,但是GPU占用反而降低到13%了,不过CPU运占用就没有去到100%。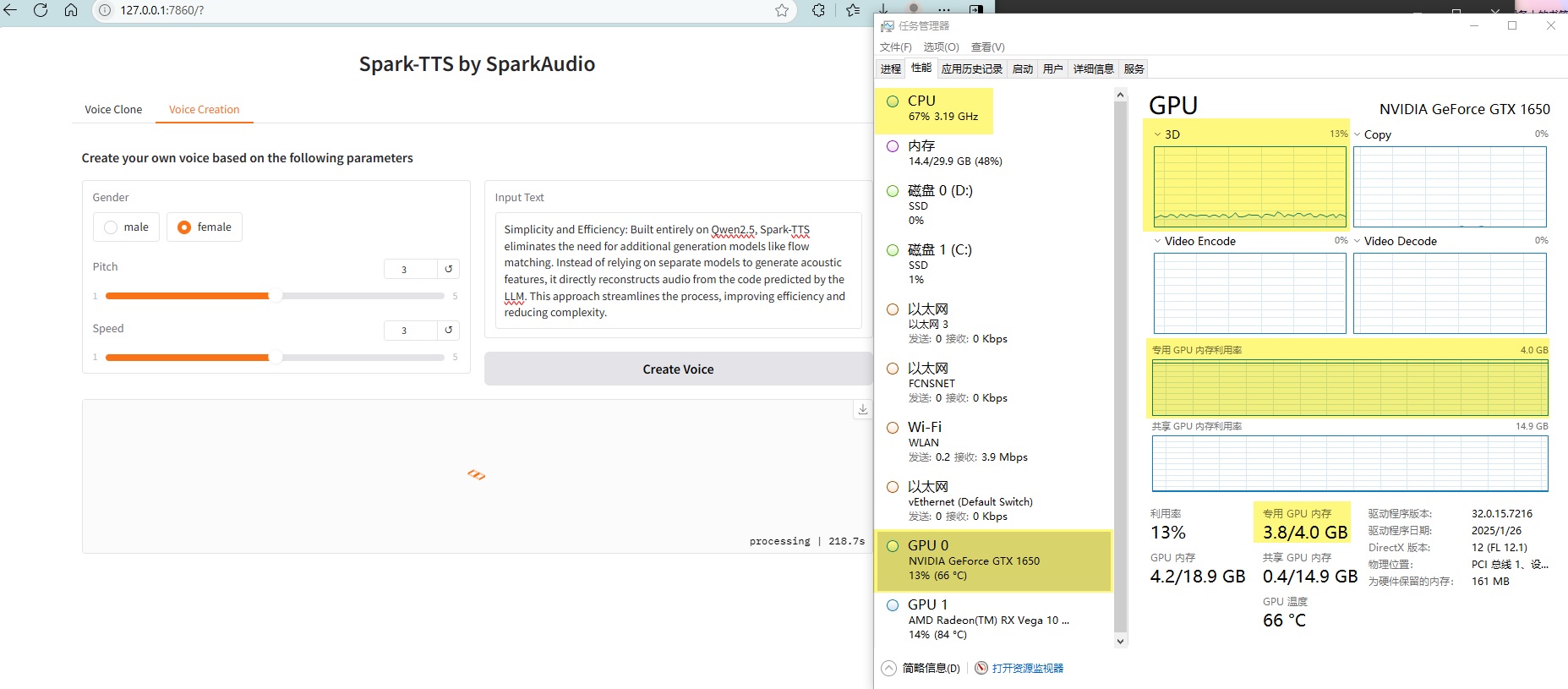
显存的占用要去到8.3G,可能需要12G显存显卡的才能跑得快。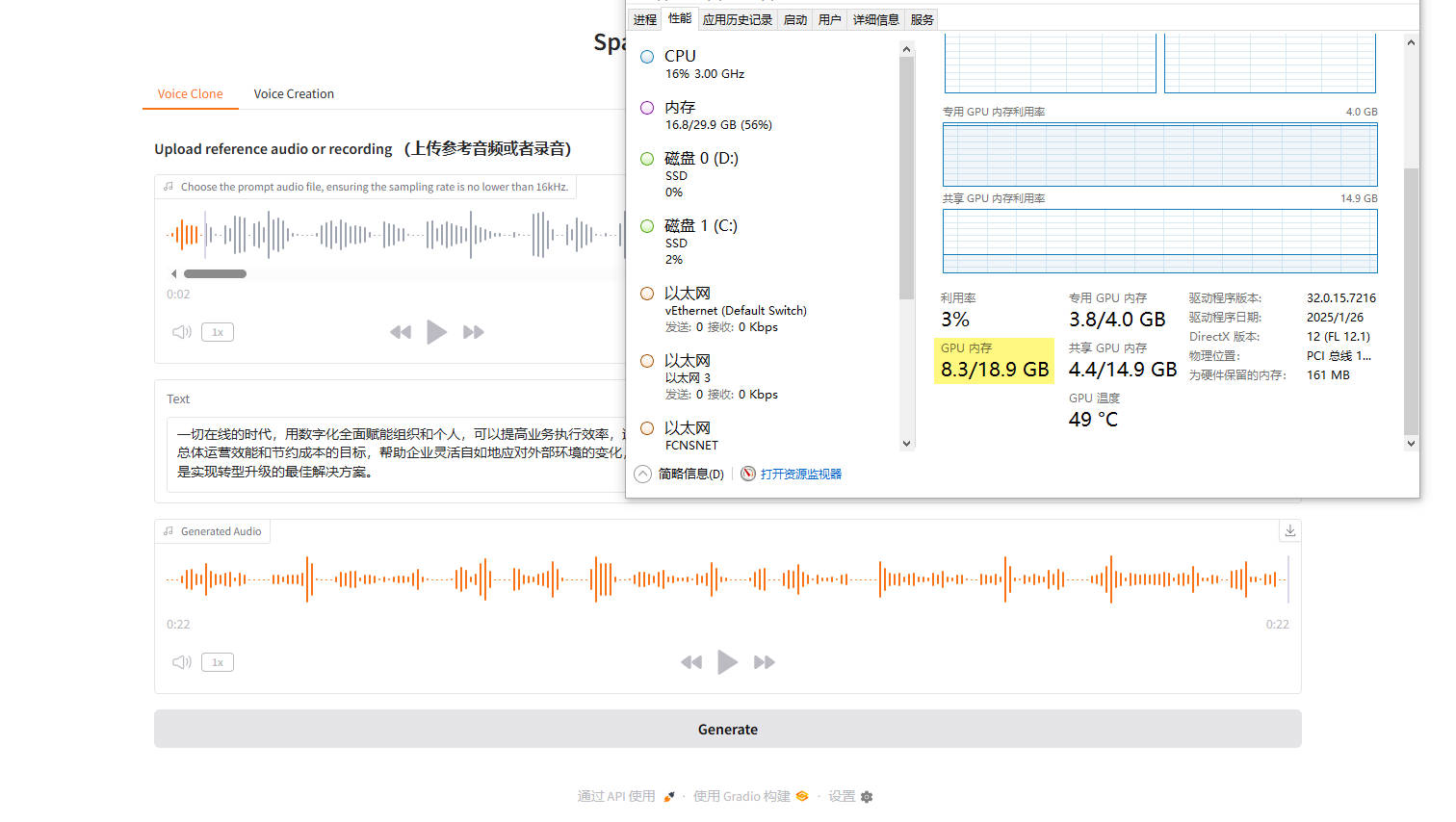
CosyVoice2(未能成功部署)
又找到一个开源的TTS CosyVoice2。下面的是测试地址,可以试用。目测也是可以本地部署的,挖一个坑,有空部署试试。
https://www.modelscope.cn/studios/iic/CosyVoice2-0.5B/?st=18HqiL89ramYJTOXUurYK1Q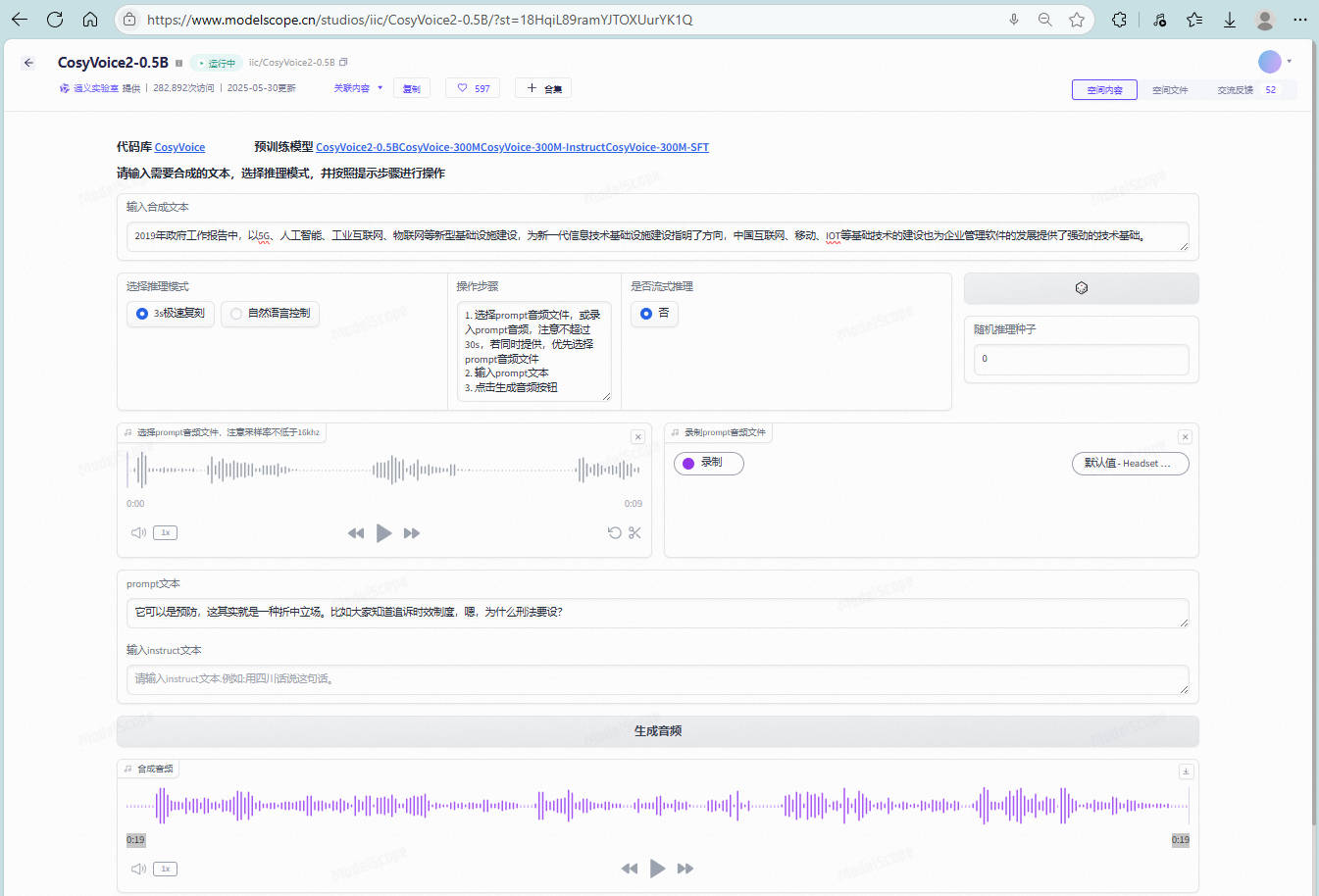
下载CosyVoice
下载地址:https://github.com/FunAudioLLM/CosyVoice
同样道理,建议用迅雷下载,并解压出来。如我的目录是:D:\AI\CosyVoice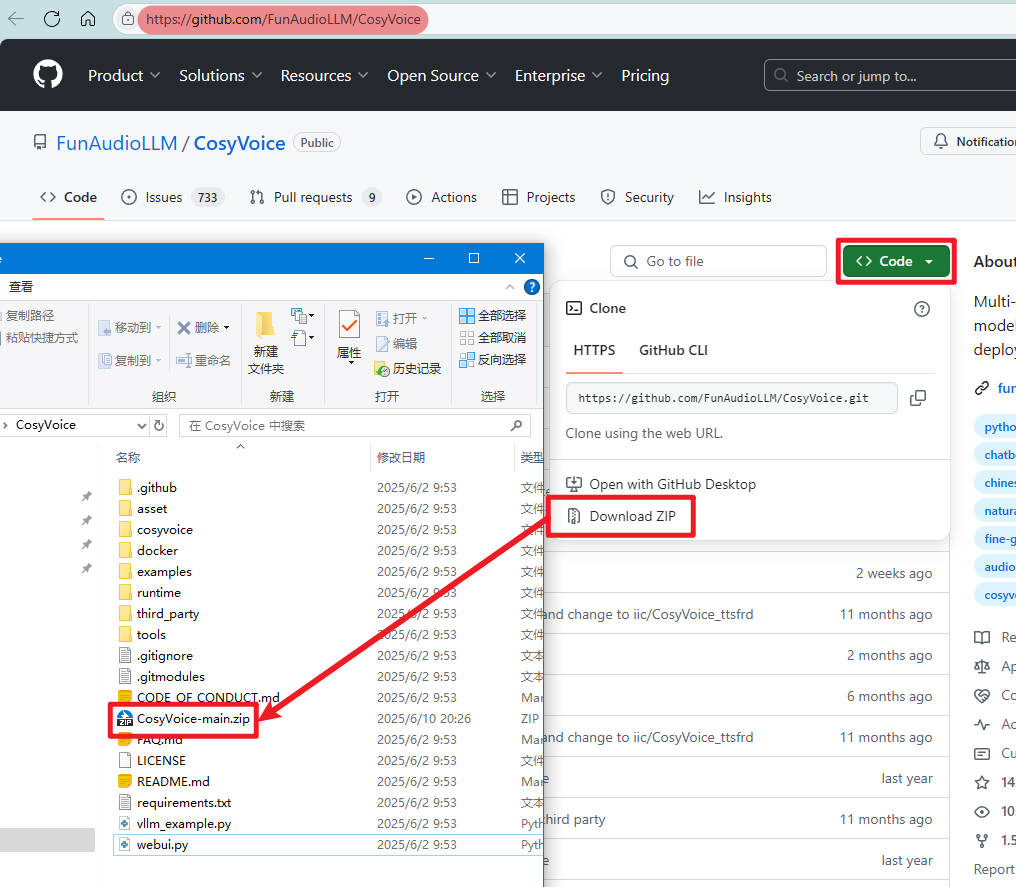
创建CosyVoice的conda环境
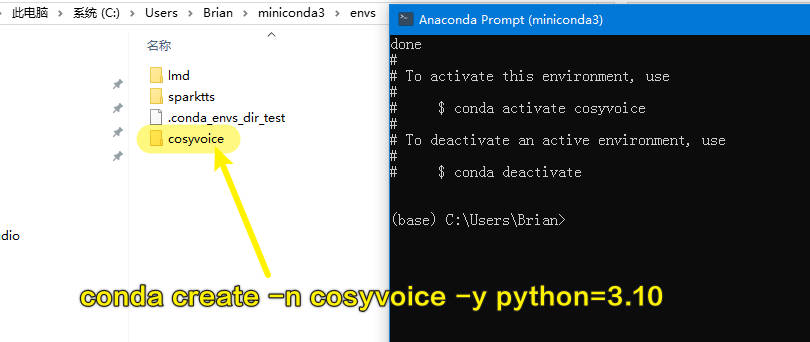
默认都安装了Anaconda了,这是用来跑Python的独立环境用的。用Anaconda Prompt (miniconda3)命令行工具来执行下面的语句。
1 | # 创建叫cosyvoice的环境 |
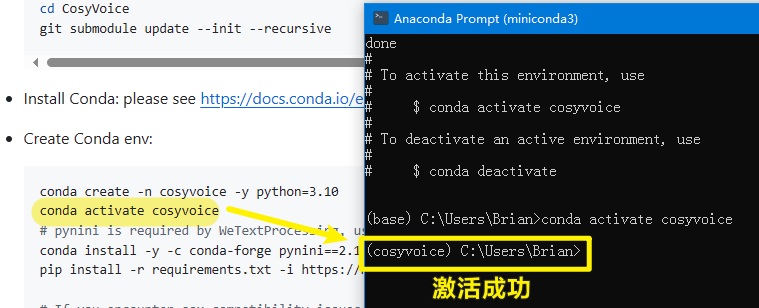
1 | # 激活这个环境 |
1 | # 安装pynini |
这条命令的作用是从 conda-forge 频道中获取并安装 pynini 软件包的 2.1.5 版本,并且在整个过程中不需要用户确认(即自动同意所有提示)。这对于需要自动化脚本或CI/CD管道中确保特定版本依赖项非常有用。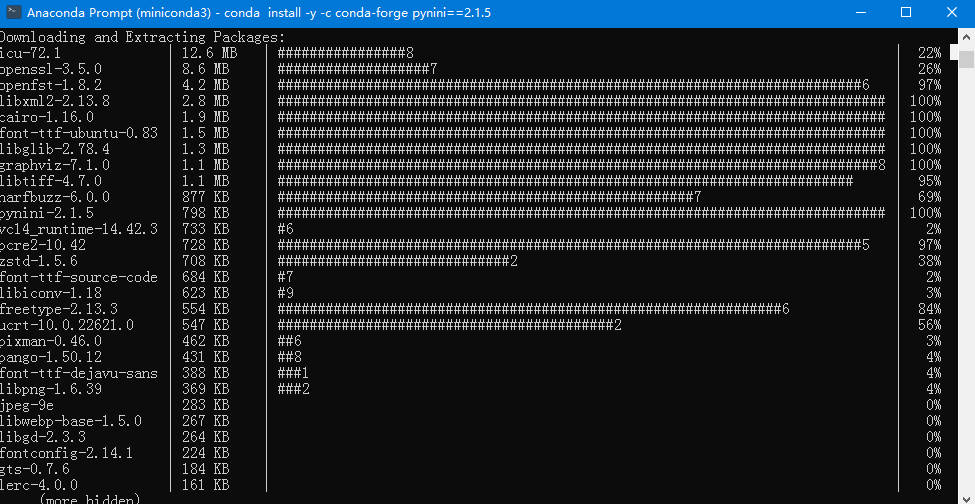
接下来要在D:\AI\CosyVoice打开终端,并执行下面的依赖更新安装。
1 | # 这个语句就是根据D:\AI\CosyVoice的requirements.txt来更新安装依赖 |
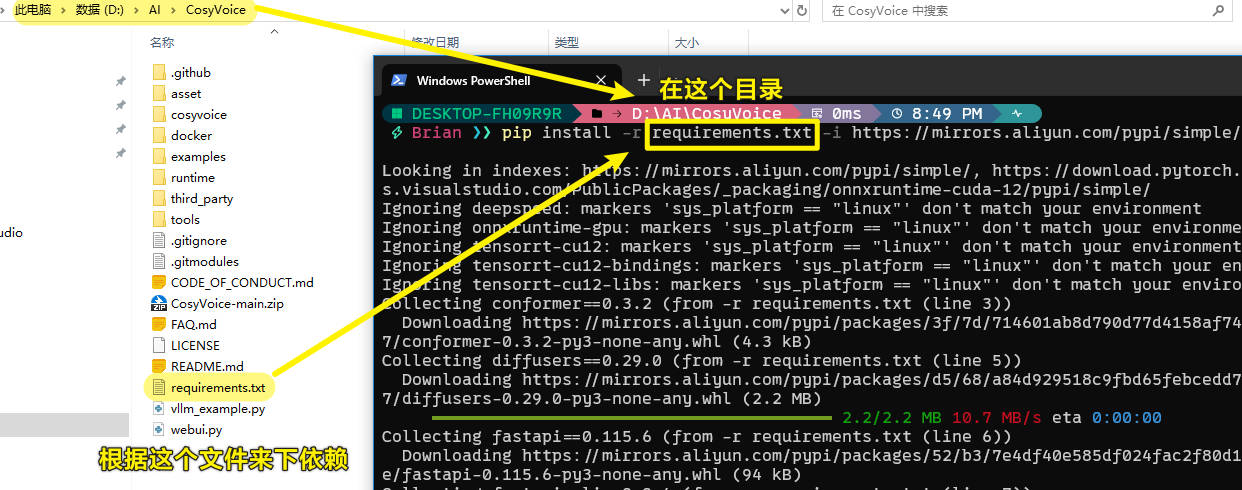
遇到这个错误,就是requirements.txt的版本太久了,换成建议比较新的就行。如下图: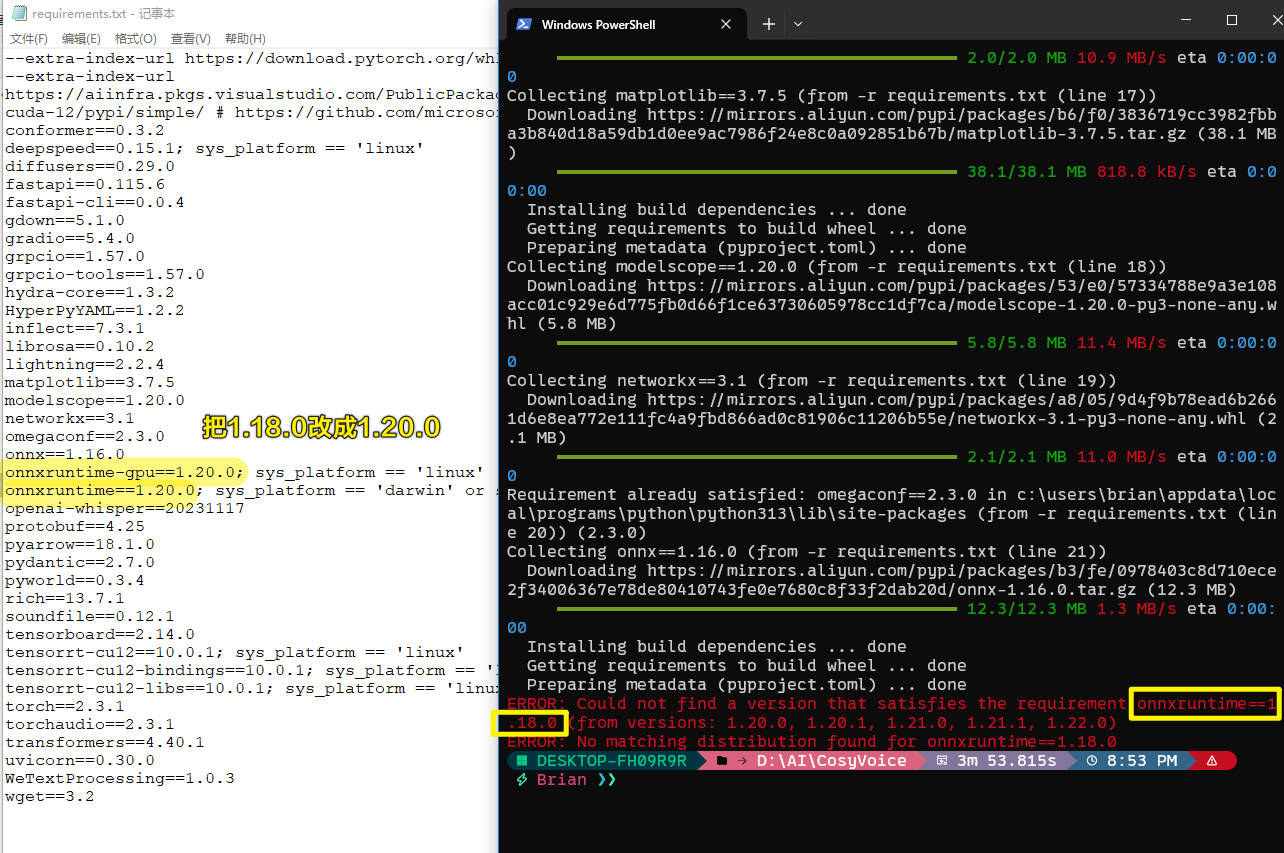
修改好requirements.txt,再执行一次语句pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com继续跑一次依赖更新安装。
Python的版本太高了,不支持,只能止步于此了?因为SparkTTS用的就是3.13,降级不知道会不会有影响。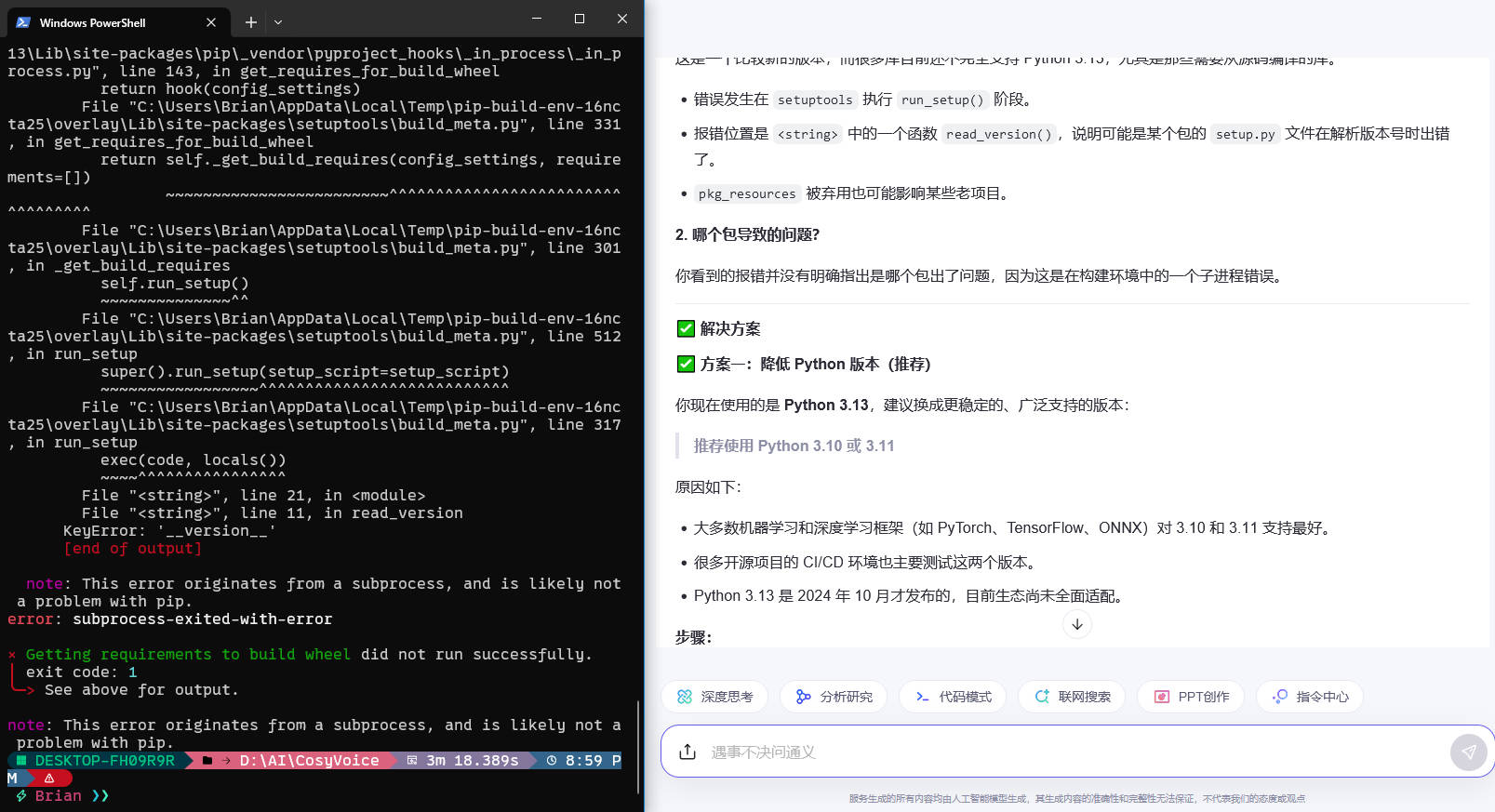
抱着试一试的想法,用Anaconda Prompt (miniconda3)命令行工具来执行试试。前提先执行conda activate cosyvoice来激活环境。
1 | # 需要切换到D:\AI\CosyVoice |
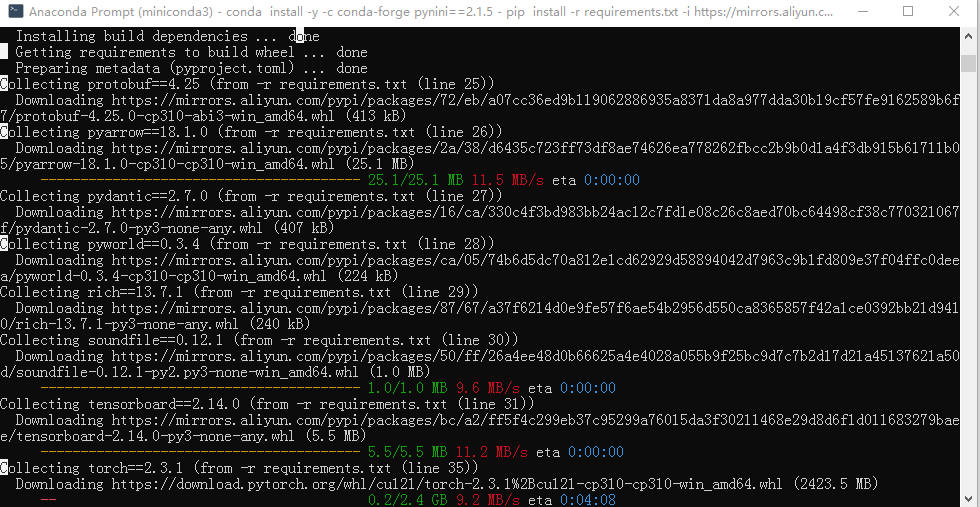
这次感觉是成功了。应该是缺了conda activate cosyvoice来激活环境后再执行命令。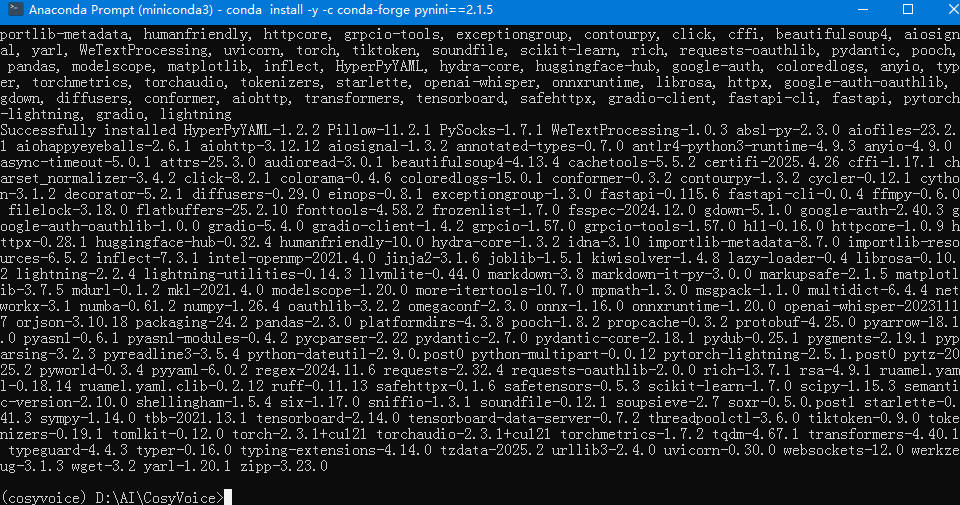
下载模型
在D:\AI\CosyVoice目录下新建一个down.py的文件,把下面的代码放进去。
1 | from modelscope import snapshot_download |
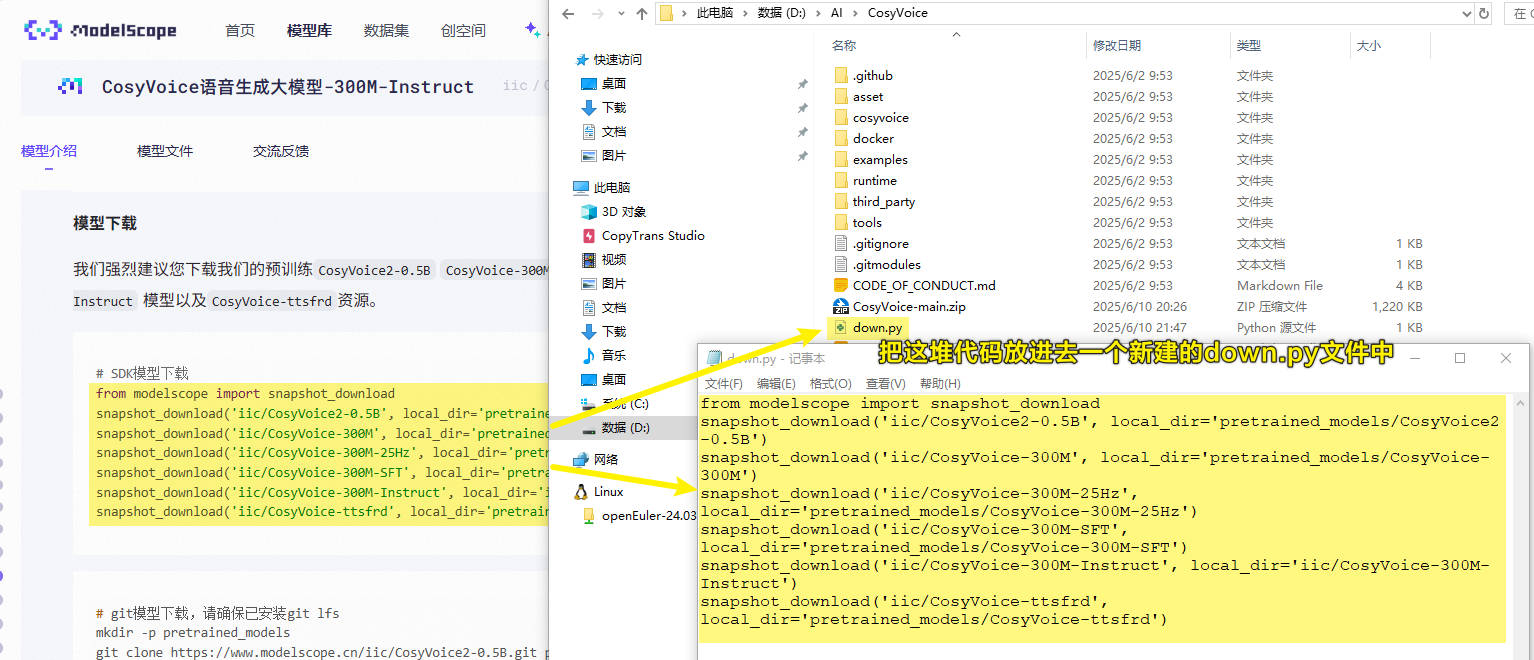
再继续执行这个文件,就会开始下载模型。
1 | python down.py |
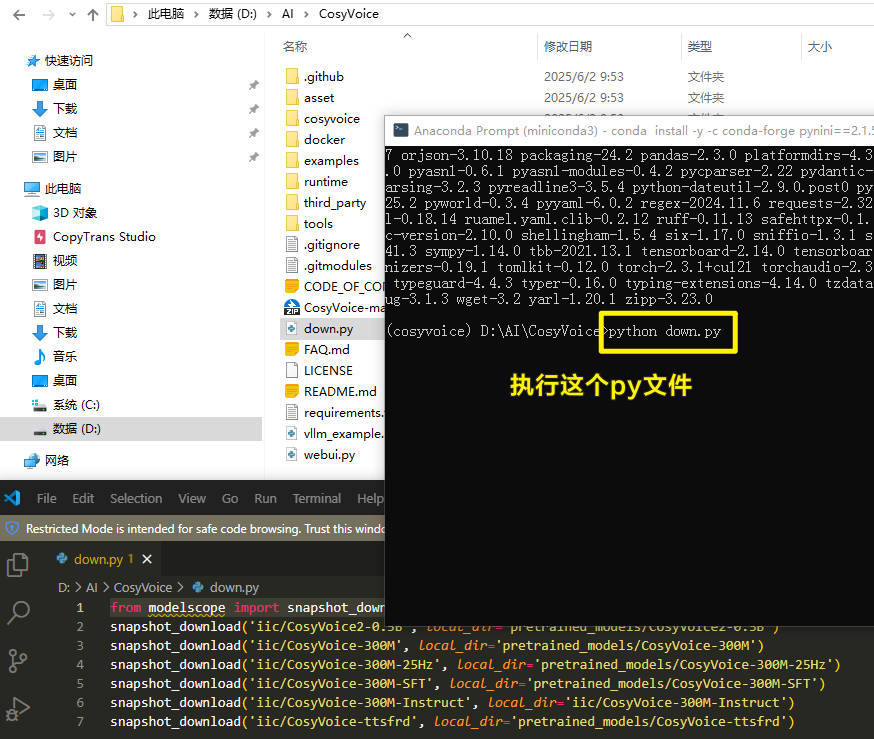
会下载在D:\AI\CosyVoice\pretrained_models这个目录中。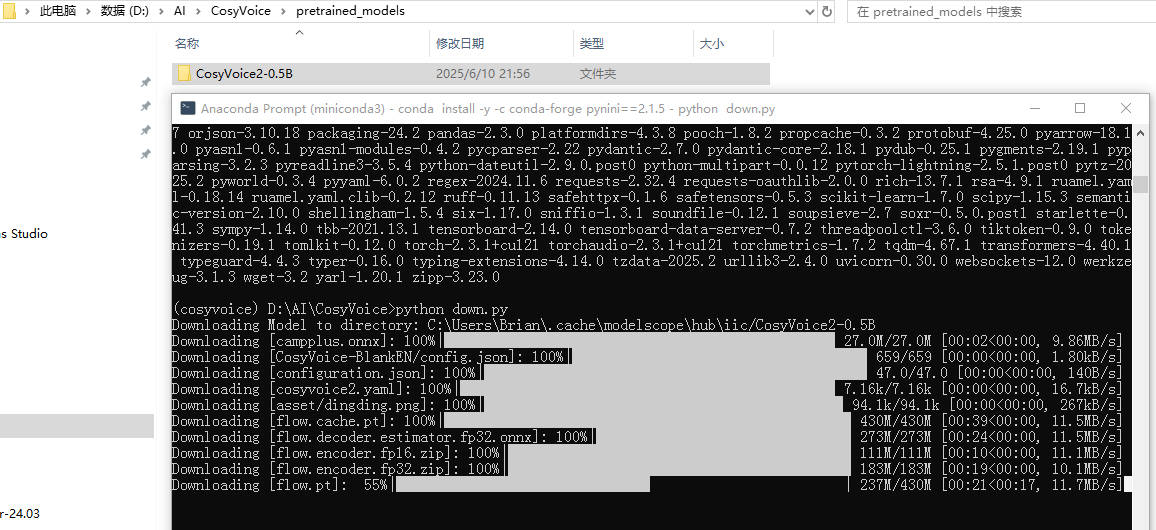
安装 Microsoft Visual C++ Build Tools
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
conda的常用命令
1 | # 创建一个conda环境,名字叫cosyvoice,PyThon版本是3.10 |
1 | (cosyvoice) DESKTOP-FH09R9R D:\AI\CosyVoice 561ms 9:45 AM |
推荐TTS免费网站和工具
【EN】https://www.naturalreaders.com
速度还不错,但是下载成MP3就需要收费了。免费用的语音是Community的音色。
【CN】剪映
有一些能用的中文和英文配音,也能保存为视频。
EasyVoice(牛B)
突然发现了一个非常好用牛B的TTS工具
GitHub:https://github.com/cosin2077/easyVoice
官网(能免费用):https://ev.xhalo.co/
最牛B的是用飞牛NAS就能部署,CPU和内存占用都极低,几乎可以忽略不计。
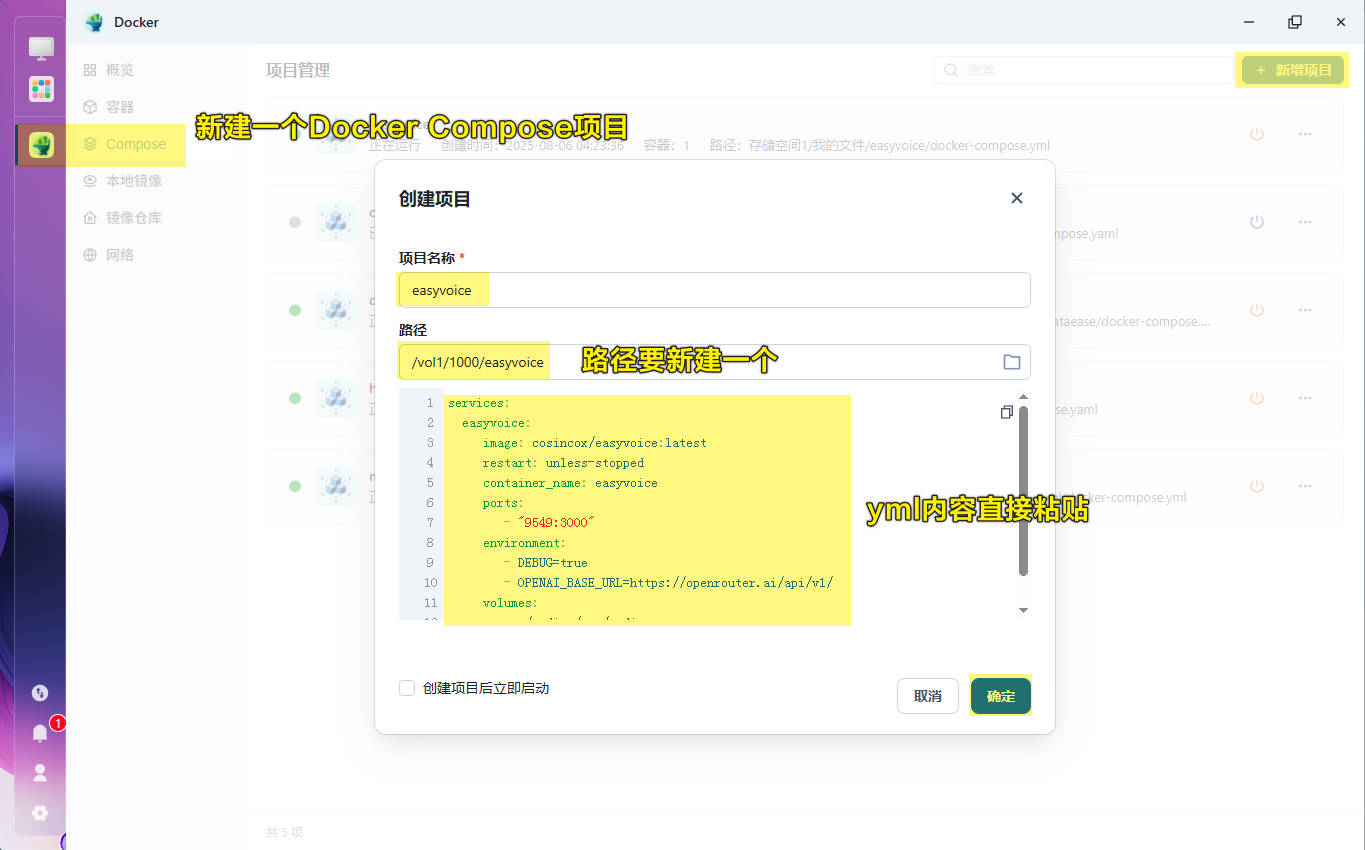
(1)新建一个Docker Compose项目
(2)配置跟我截图一模一样即可。
(3)yml文件直接粘贴我的代码:
1 | services: |
启动这个Docker Compose项目。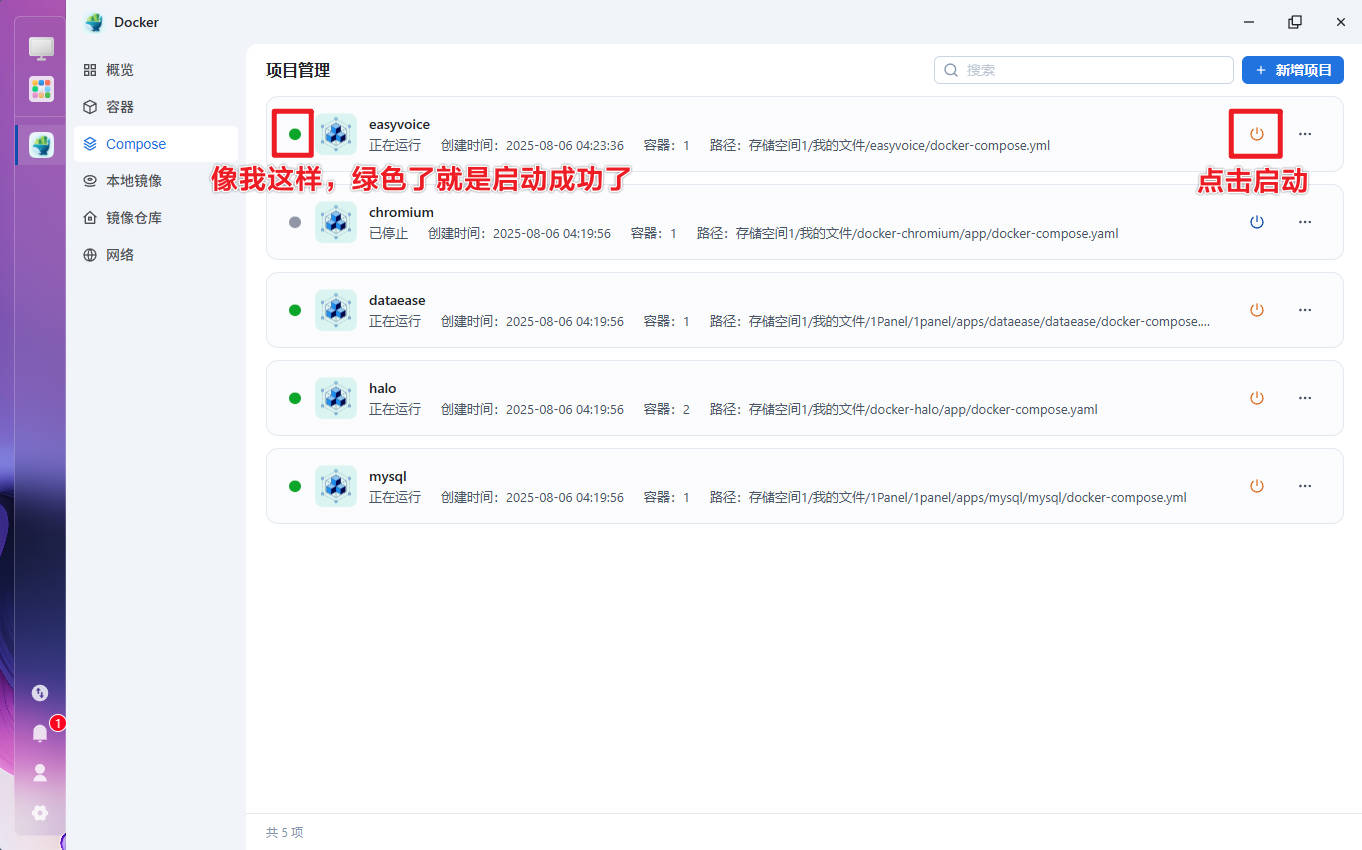
浏览器进入你的飞牛IP:9549,你就能看到跟官网一模一样的功能了。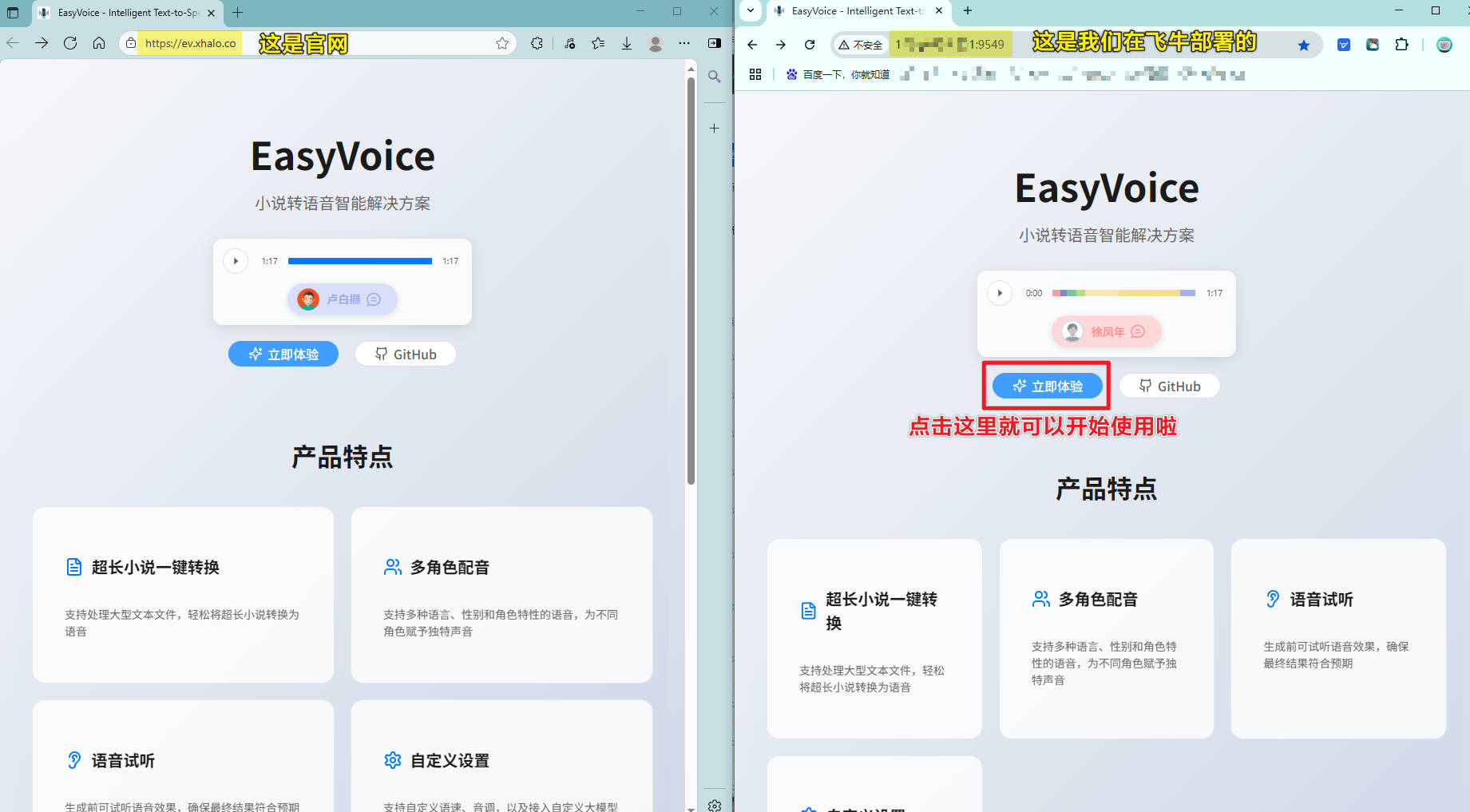
测试可用,秒生成,CPU占用几乎为0,内存占用看不出来,因为我开了好几个Docker应用。
PS:因为这个应用没有用户名密码保障,发布到公网要小心被玩坏。建议作者加上账号登录。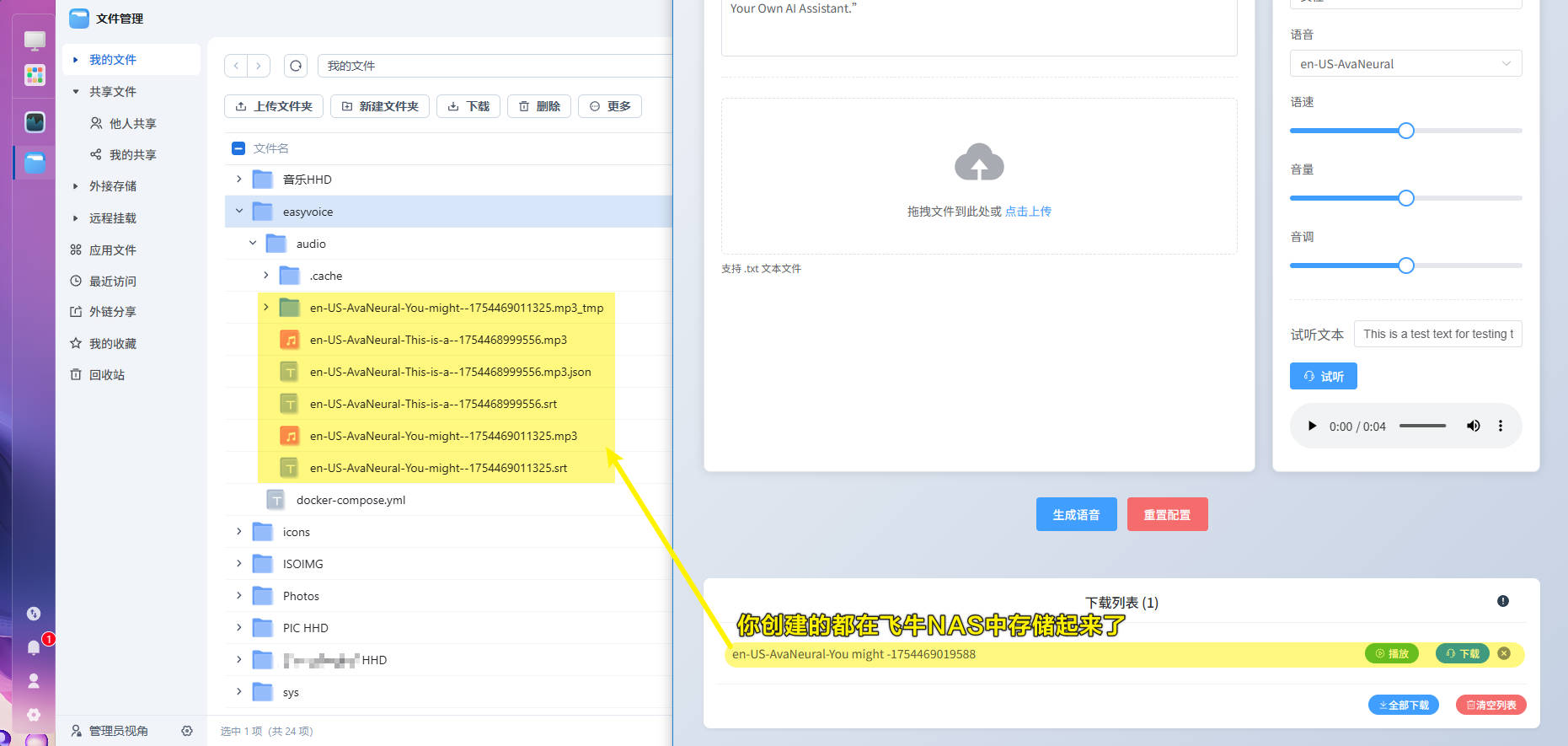
AutoCaption On Gummy(阿里百炼)实时翻译
项目地址:https://github.com/HiMeditator/auto-caption
下载地址:https://github.com/HiMeditator/auto-caption/releases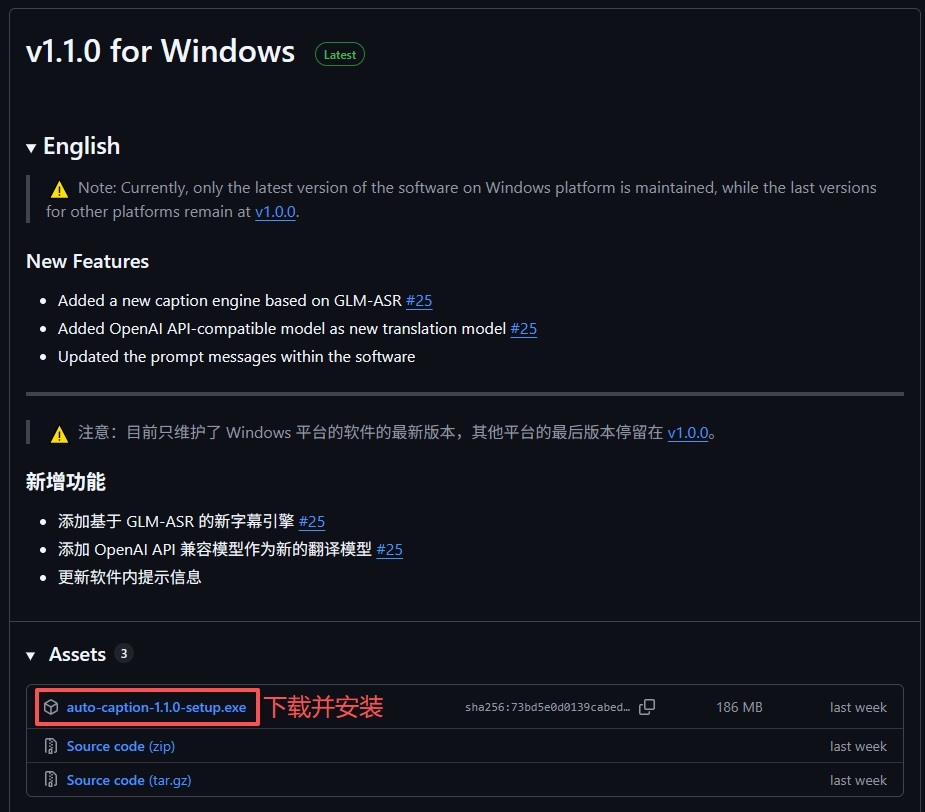
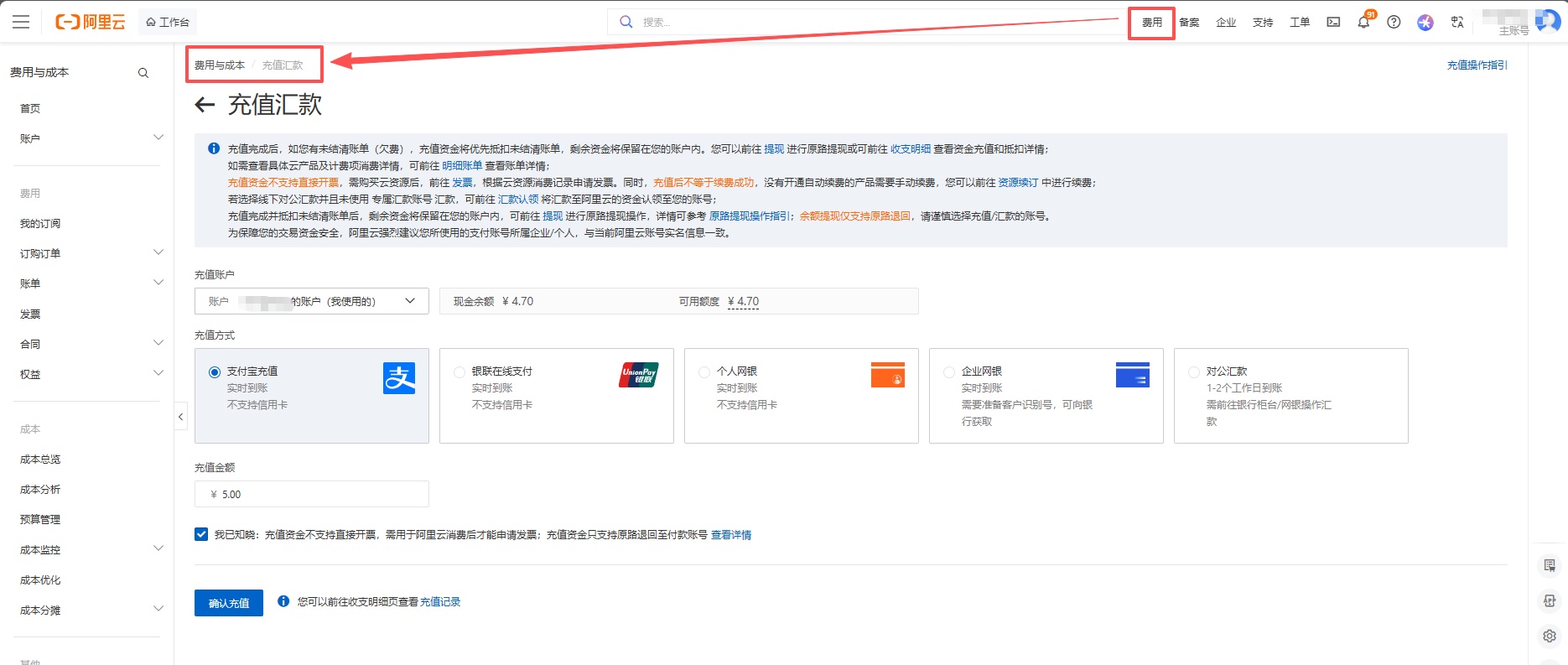
使用前必须先要登录了阿里百炼账号(跟支付宝一样的账号即可)
充值,建议先充个5元测试一下,然后测试一下Gummy(实时语音识别及翻译V1.0)模型能能不能用。
搜索Gummy
立即体验进入测试,按报价一小时大概0.54元,比讯飞便宜超级多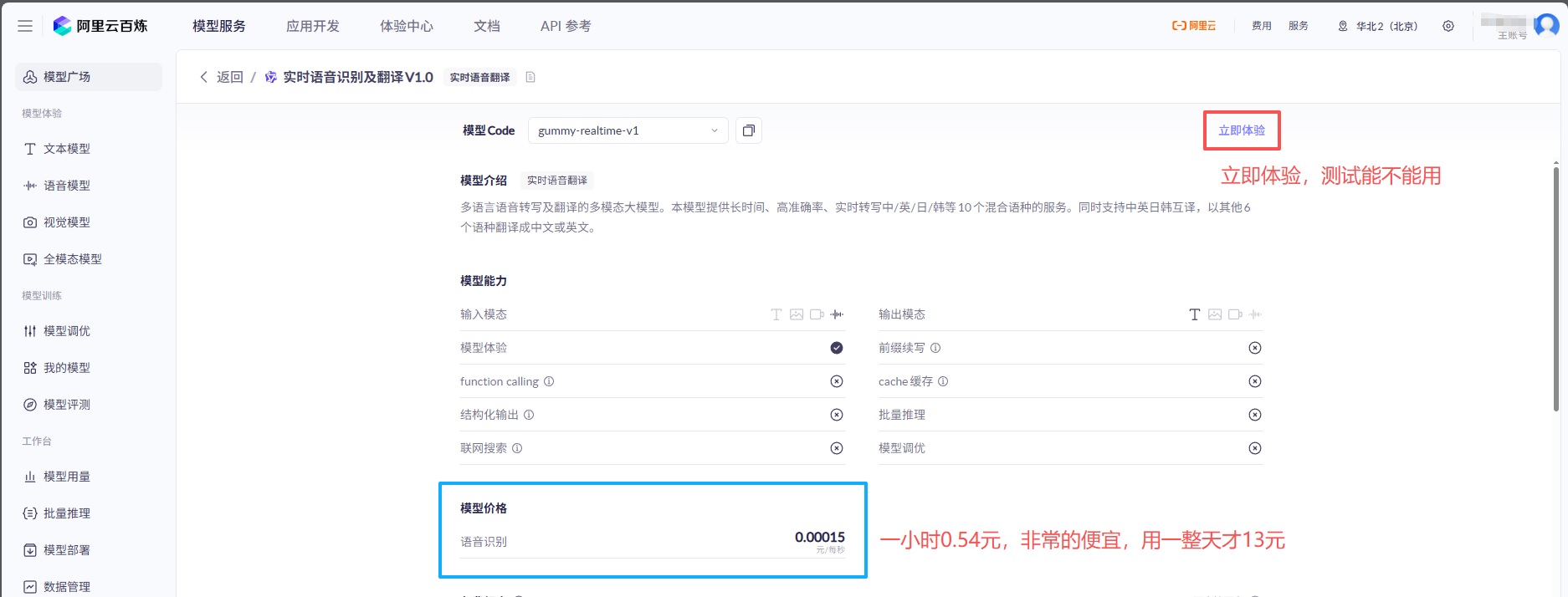
确认选择的模型开始体验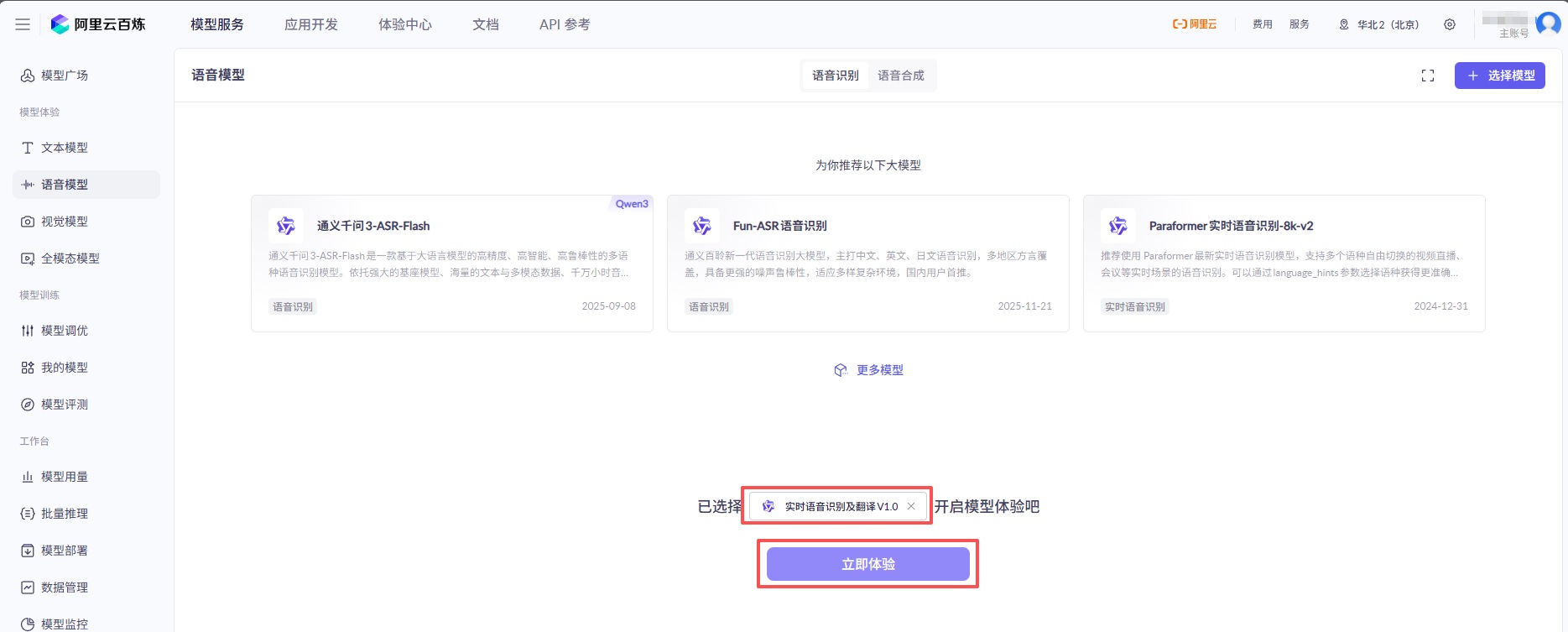
点击开始录入就正式开始计费了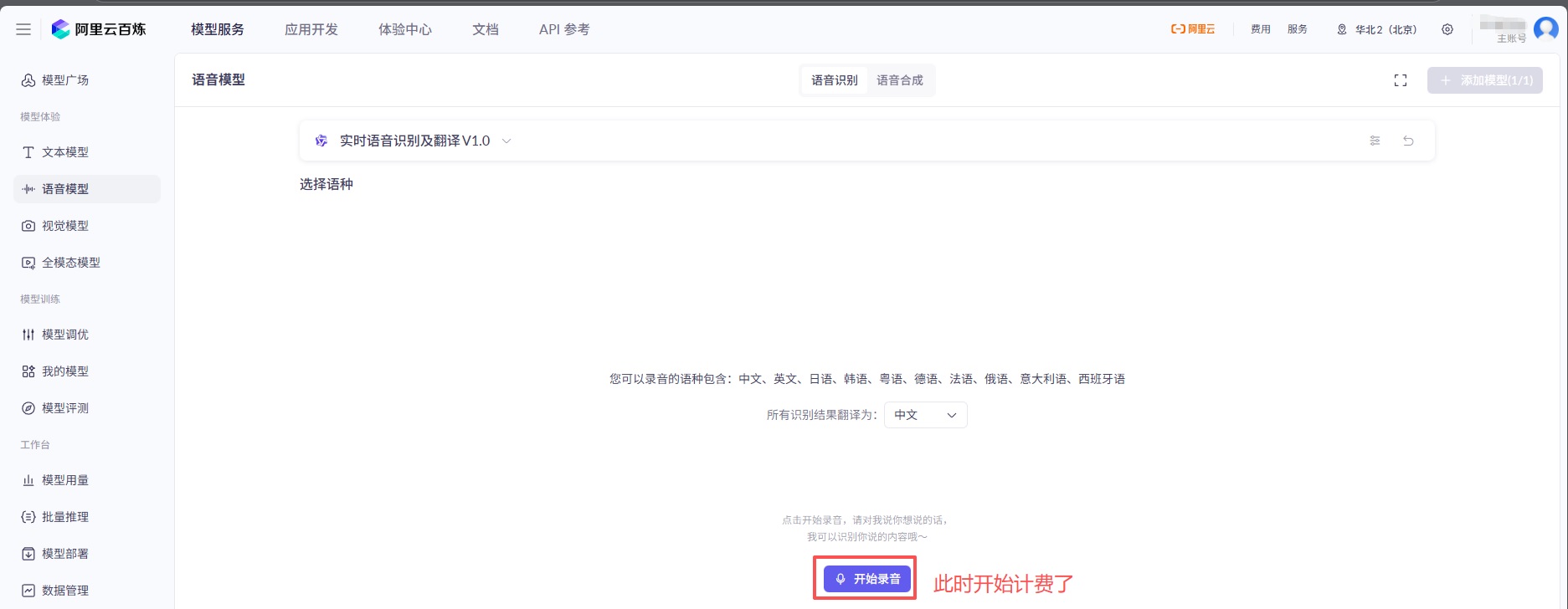
看着效果是测通了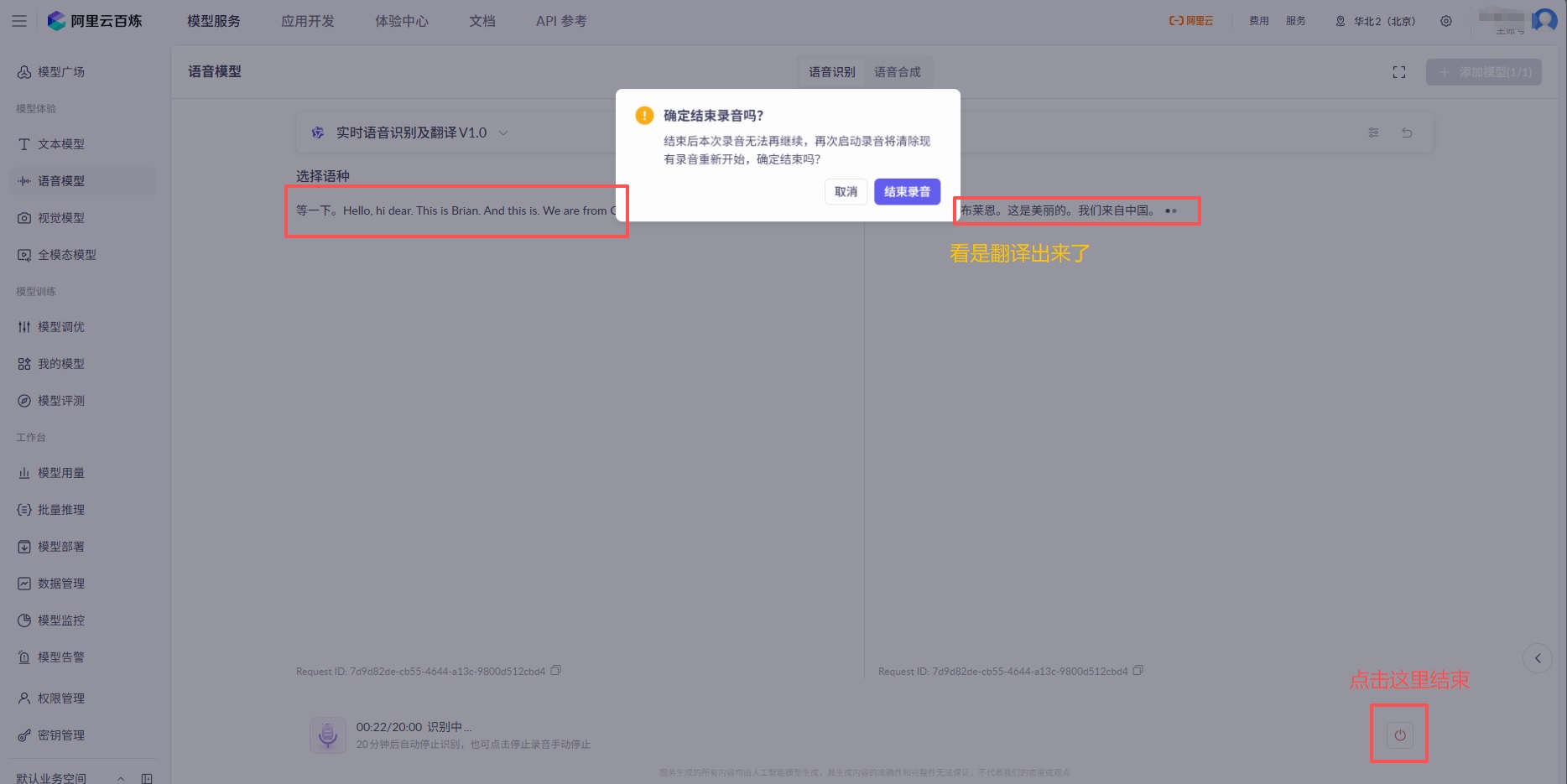
获取API KEY :https://help.aliyun.com/zh/model-studio/get-api-key

把你得到的API KEY加入系统变量 :https://help.aliyun.com/zh/model-studio/configure-api-key-through-environment-variables#e4cd73d544i3r
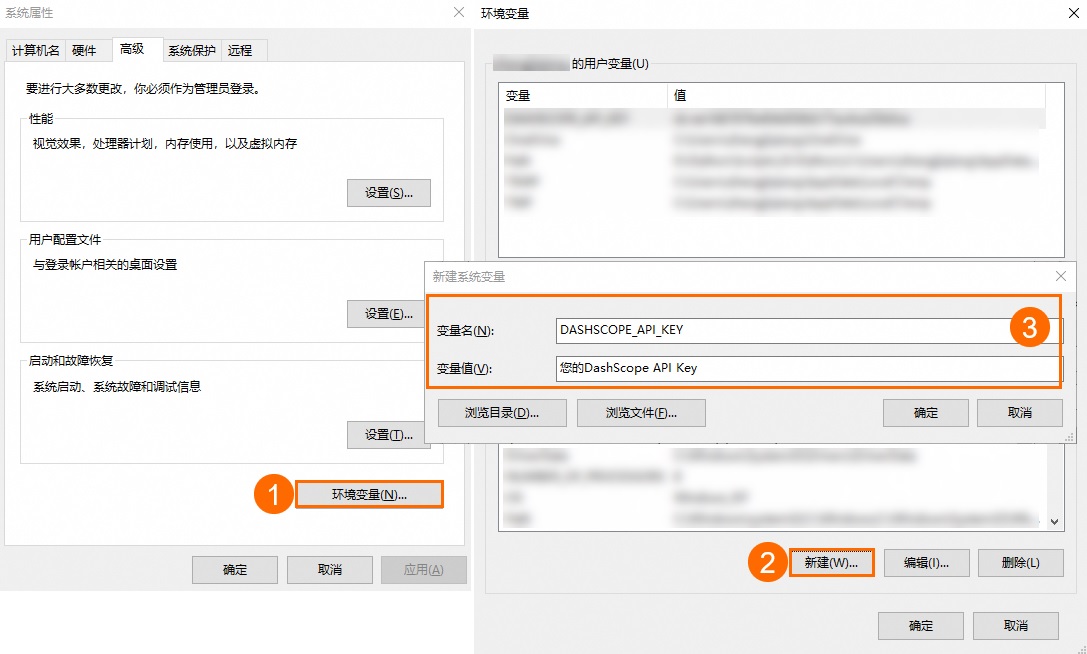
按下图配置好
- 【字幕引擎】选择
云端/阿里云/Gummy - 【更多设置】要填上
ALI API KEY - 记得点击【应用更改】
- 打开一个(英文)视频,点击【启动字幕引擎】,看看有效果不
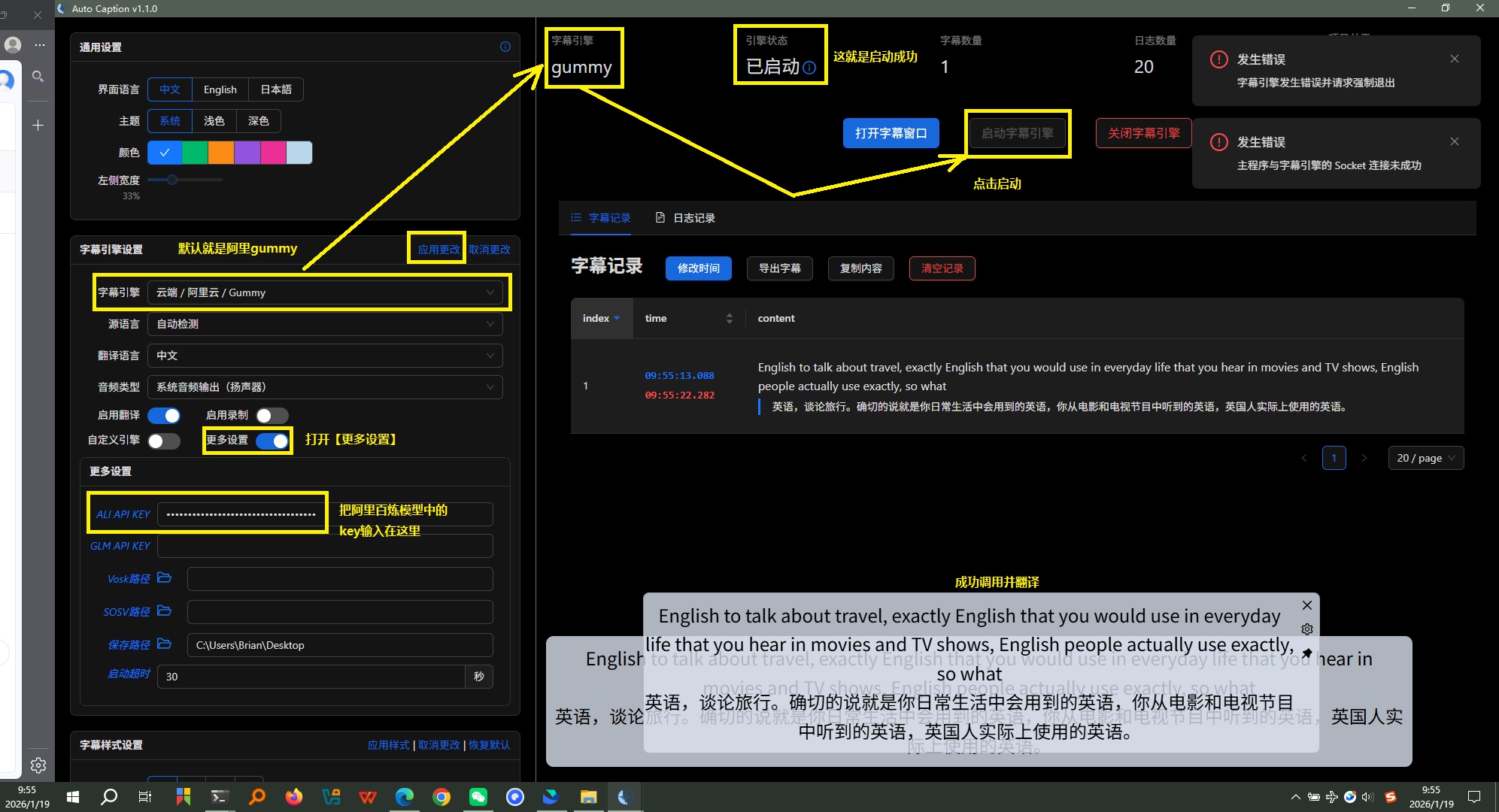
- 【字幕引擎】选择